Summary
Introduction
We present results of DABS implemented of Apache Storm. DABS is composed of a custom scheduler named AUTOSCALE+ and a custom grouping solution denoted OSG. We tested DABS against alternative schedulers and grouping solutions.
The incremental scheduler (incr) adapts the parallelism degree of operators according to the ratio input/processing rate. This rate is computed from averages values on recent history for each operator.
If this ratio is strictly greater than an upper relative bound (e.g., 80%), it increases the parallelism by one. At the opposite, if this ratio is strictly lower than a lower bound it decreases the parallelism degree by one (if possible).
The reinforcement learning scheduler (rlearn) adapts also the parallelism degree of operators according to the ratio input/processing rate averaged on recent operator's history. Nevertheless, the new parallelism is selected accordingto a knowledge
specific for each operator. A knowledge base is a set of rules updated and extended at runtime each time a new rule is generated. A rule is a quadruplet following the schema operator->state->degree->reward where a state is an interval of input rates and the reward
corresponds to the ratio input/processing rate mentioned above. Considering same operator and state, a rule r1 is better than r2 if the reward of r1 is closer to 1 by inferior value than the reward associated to r2.
It means that applying r1 instead of r2 fits the processing rate to the input rate with more accuracy and prevents congestion. Each time a rule with a new state is generated, it is added to the knowledge base.
In addition, each time a rule associated to a known state but with a better reward than the existing one is generated, the old rule is replaced by the new one.
The shuffle grouping (shuffle) distributes tuples among replicas of an operator in a Round-Robin fashion without consideration for the value.
Experimental parameters are summarized in the following table:
|
Test streams
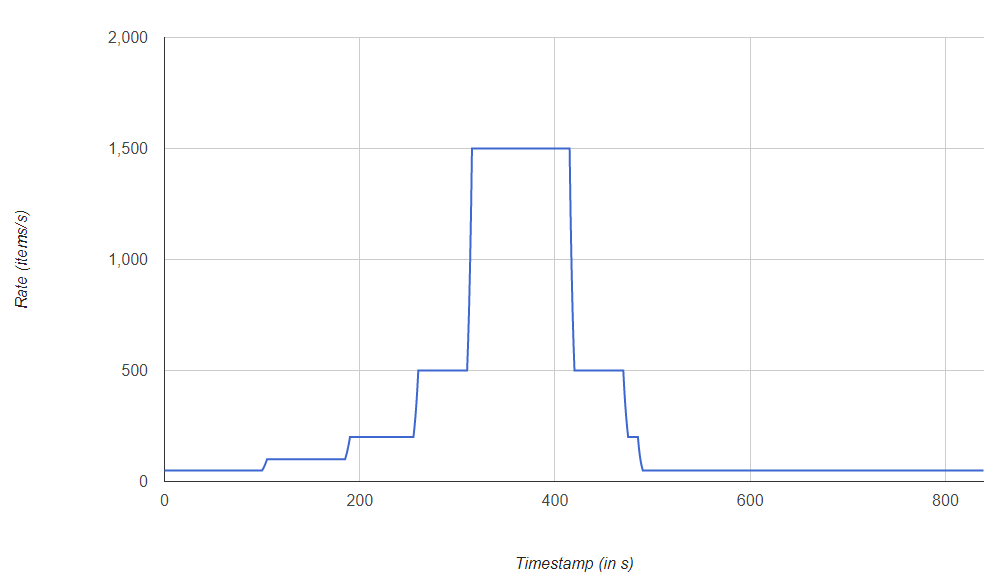 | 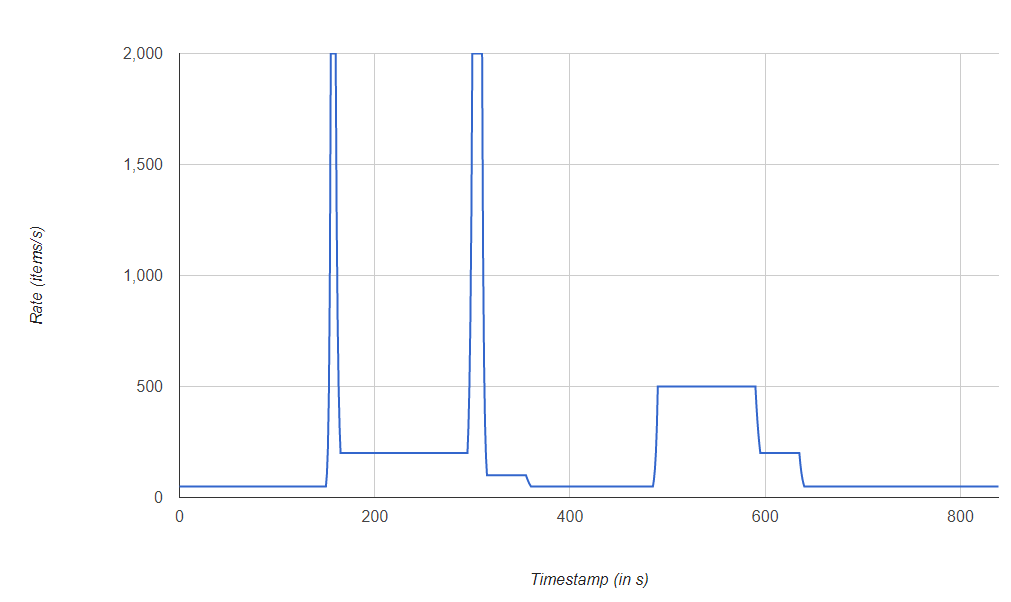 |
We applied the three streams illustrated above to evaluate auto-parallelization of operators according to the selected strategy. Respectively from left to right, the constant stream emits a fixed number of stream elements for a predefined period.
Then, the progressive stream emits an increasing number of stream elements per second until it stabilizes to a maximal value before decreasing deeply. Finally, the erratic emits stream elements at rates increasing and decreasing deeply on a short period of time.
Results
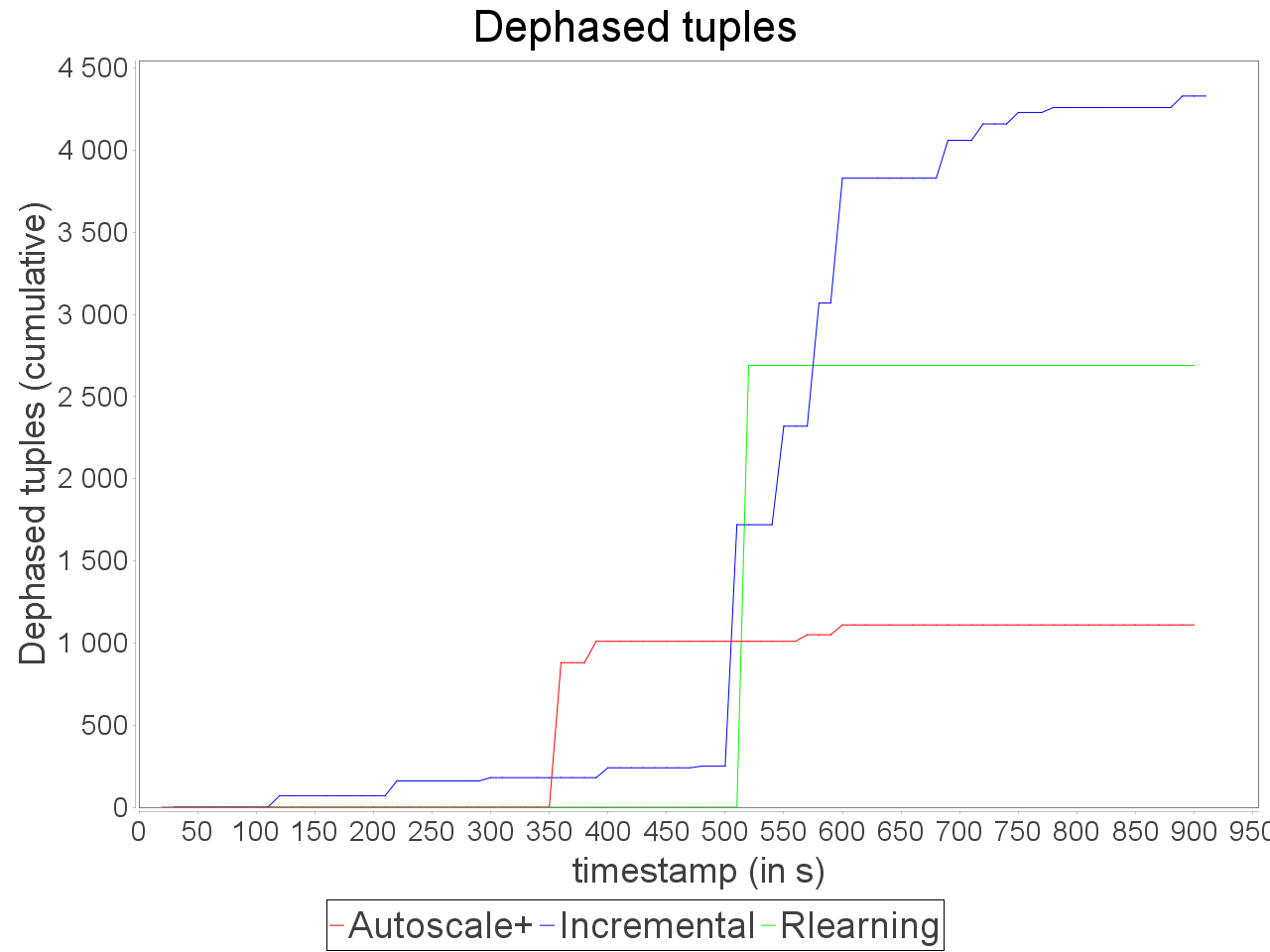
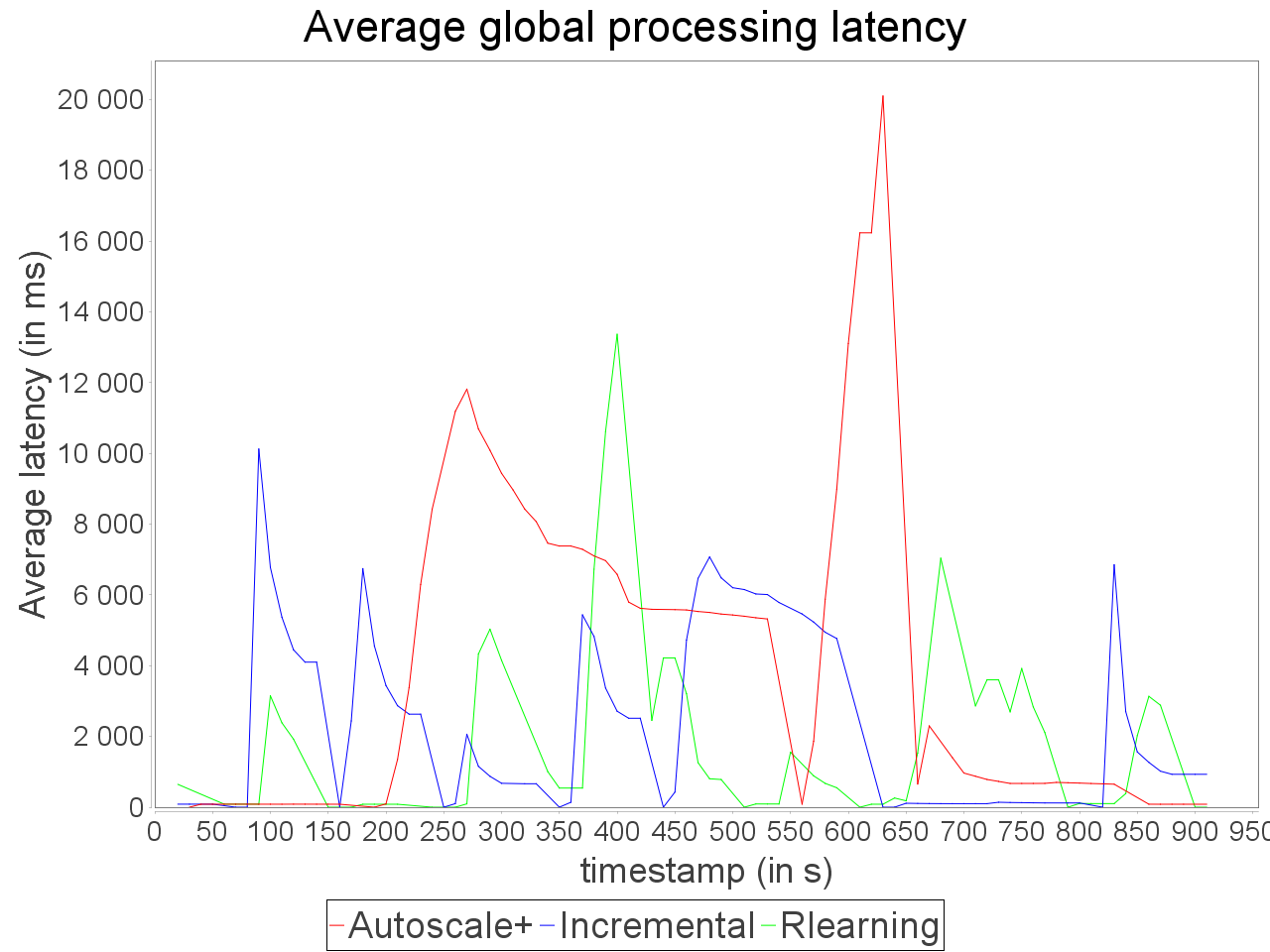
Simple insensitive topology: progressive stream
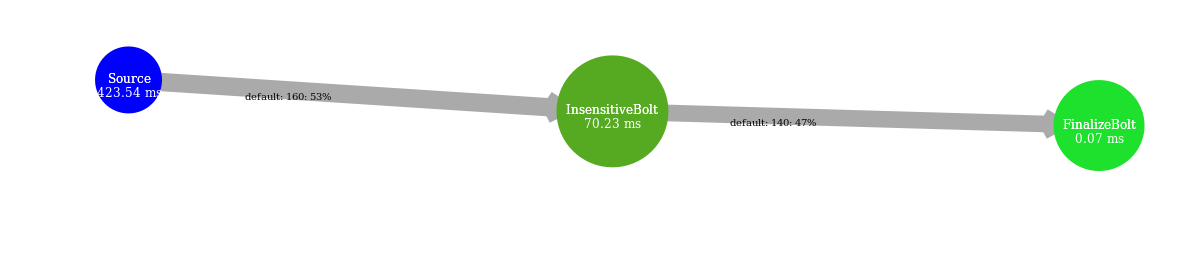 | |
 |  |
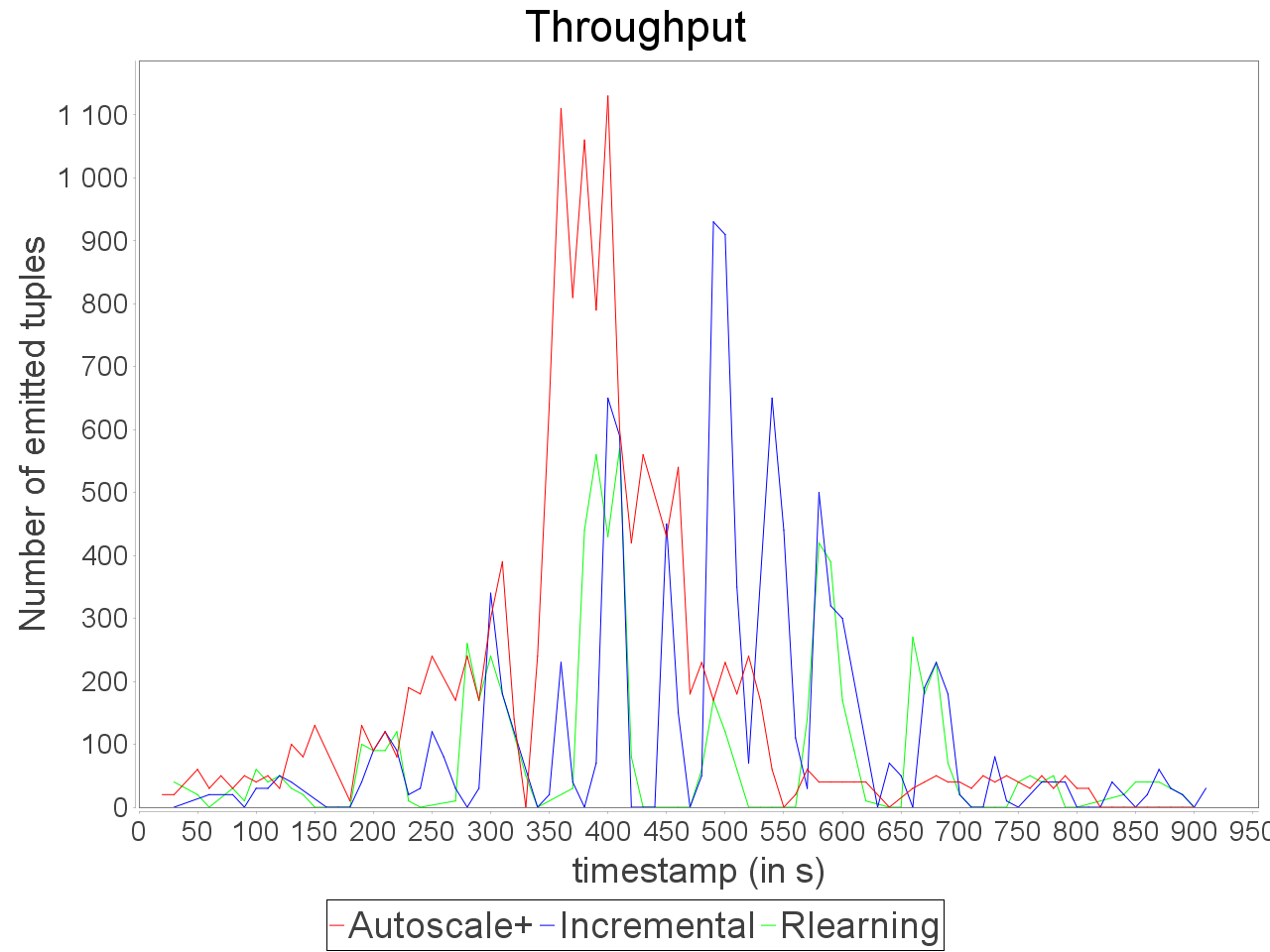 | 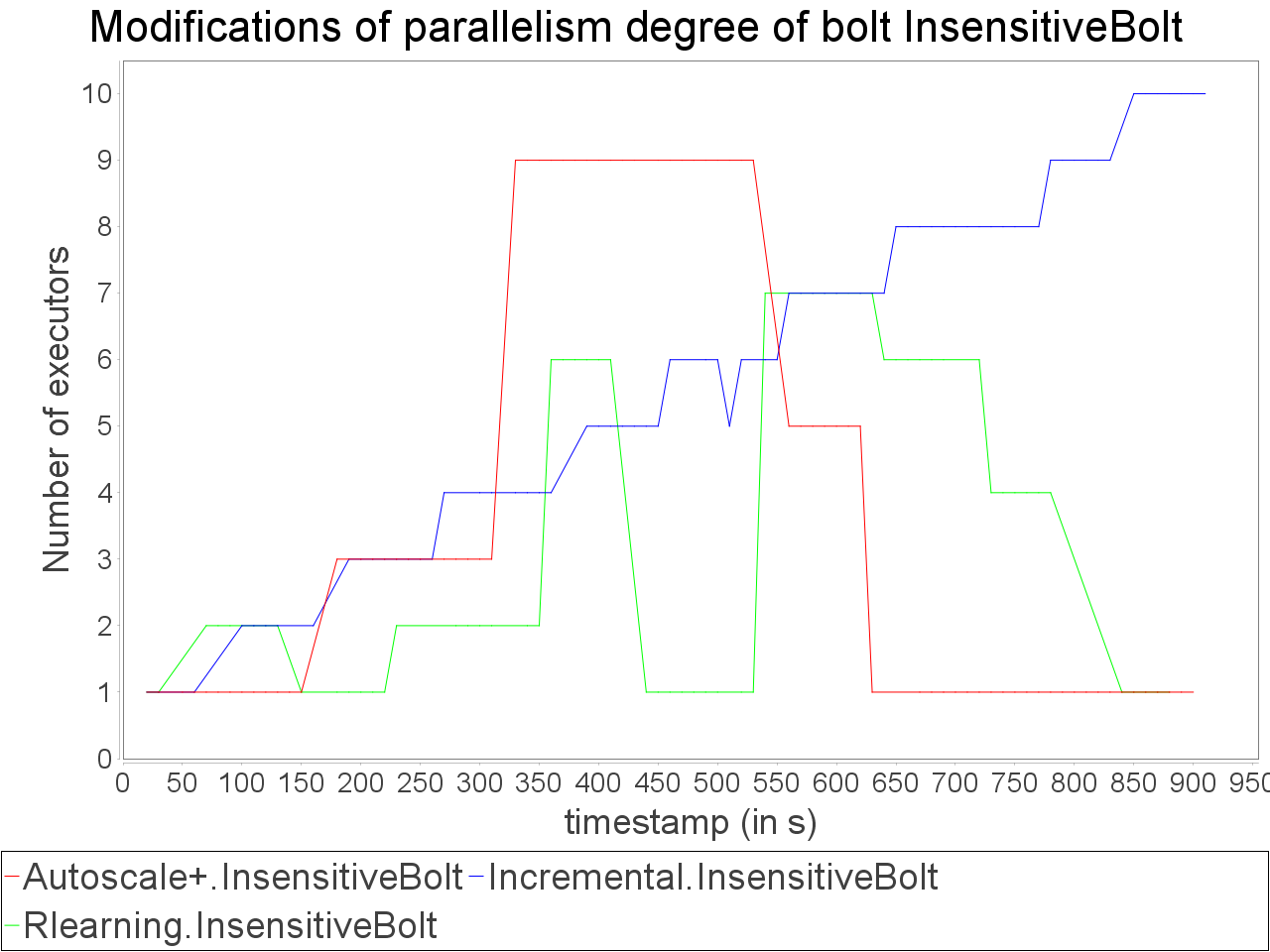 |
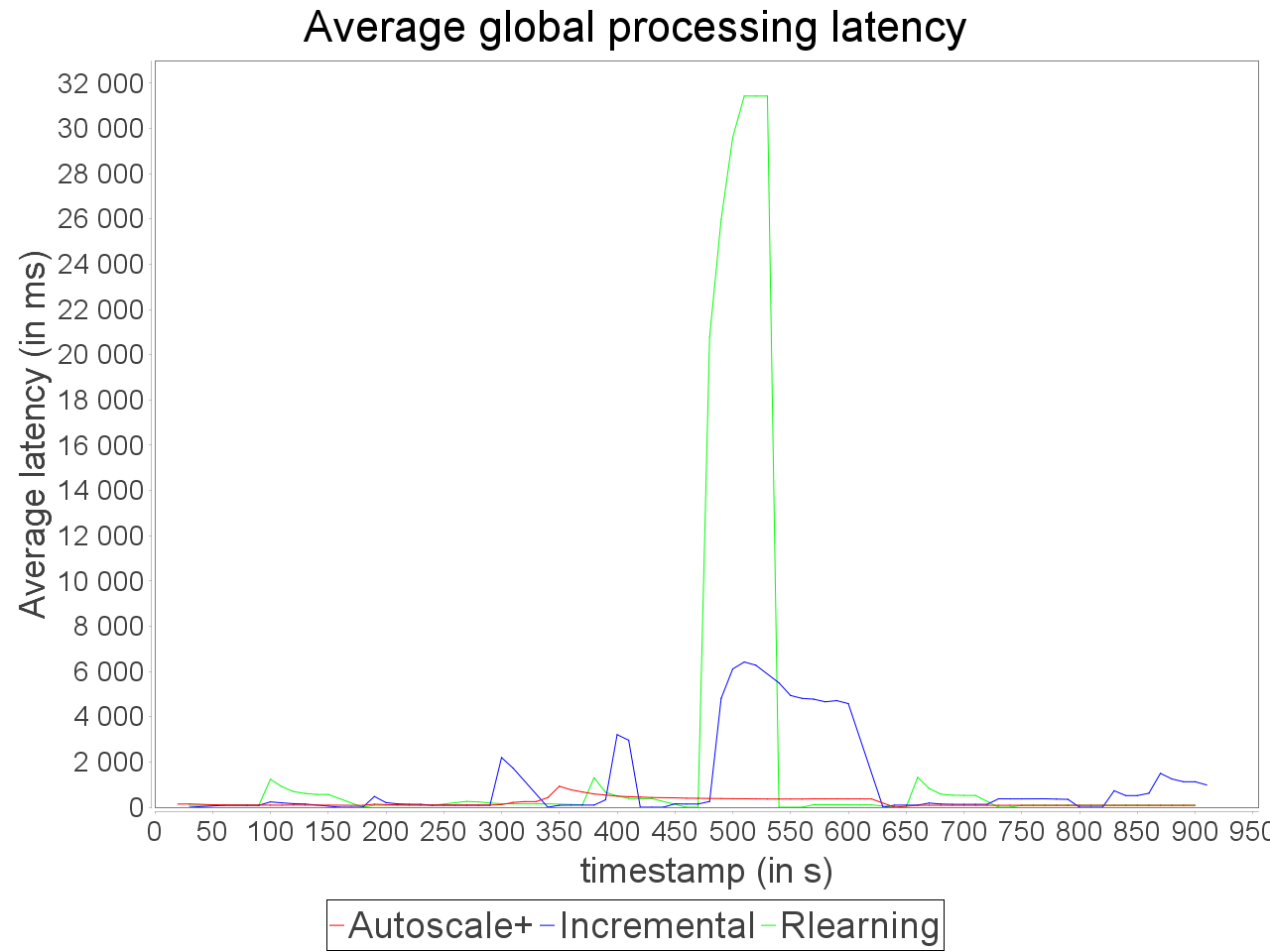
On the same topology, we applied a stream increasing and decreasing progressively and test AUTOSCALE+ in front of incremental and reinforcement learning schedulers (AFTER learning phase). We observe that the preventive adaptation performed by AUTOSCALE+ has less impact on
global latency than reactive reconfiguration performed by incremental and learning strategies. AUTOSCALE+ also maintains a throughput higher than reactive strategies because it anticipates processing requirements and lightly overestimate parallelism degrees as we can see in comparison of reinforcement learning strategy
which never exceeds 7 executors for the critical operator while AUTOSCALE+ goes up to 14 executors on a short period. Nevertheless, it is worth noting that the reinforcement learning strategy is not able to avoid an important increase of the latency when the input rate is at its maximum value. Concerning the incremental strategy,
its lack of reactivity in front of stream fluctuations turns to an advantage as small increases of parallelism degree have less impact on processing latency. However, when both AUTOSCALE+ and reinforcement learning strategies detected that resource usage can be reduced, the incremental strategy is still overconsuming resource.
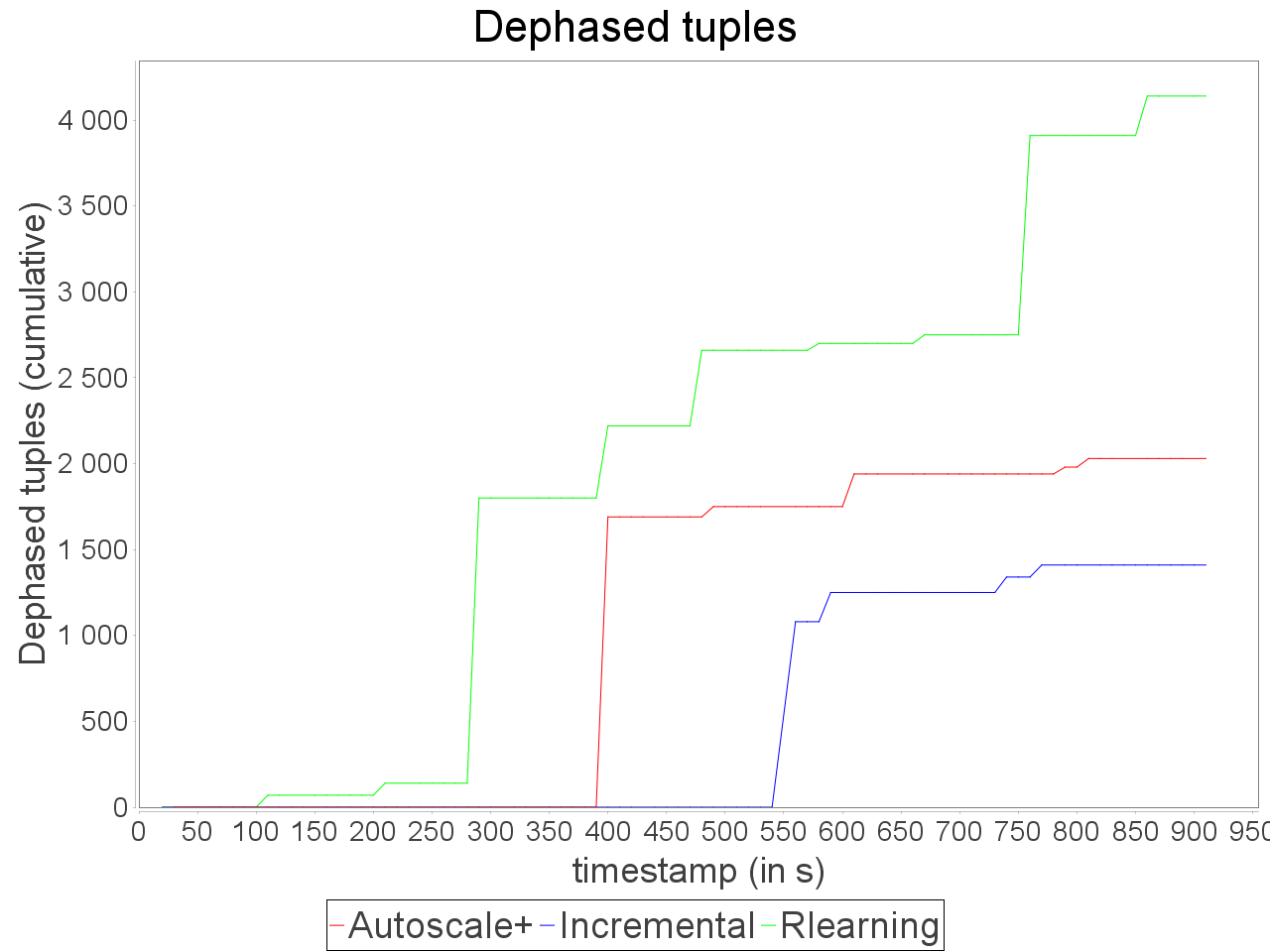
Simple insensitive topology: erratic stream
| |
 |  |
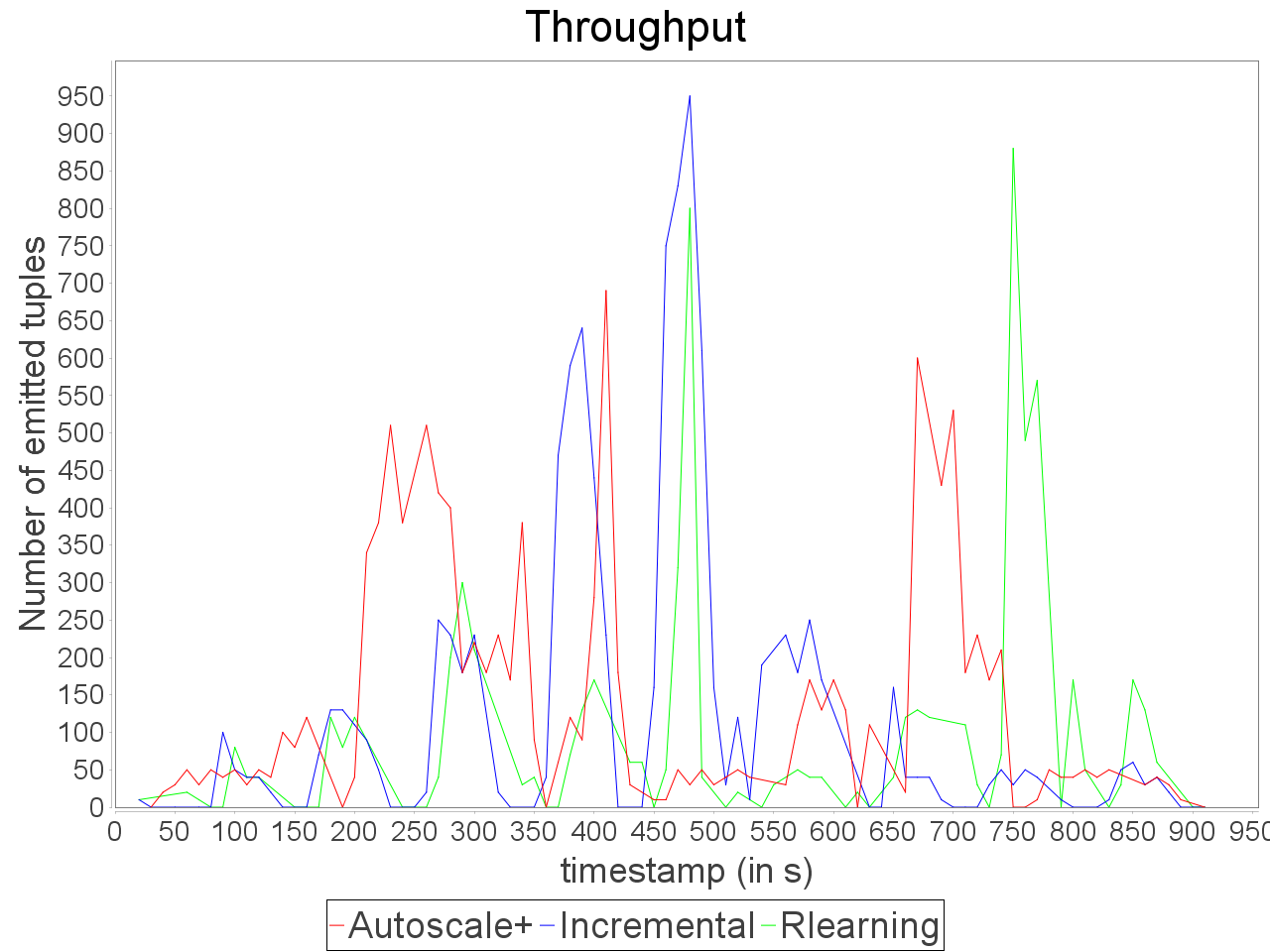 | 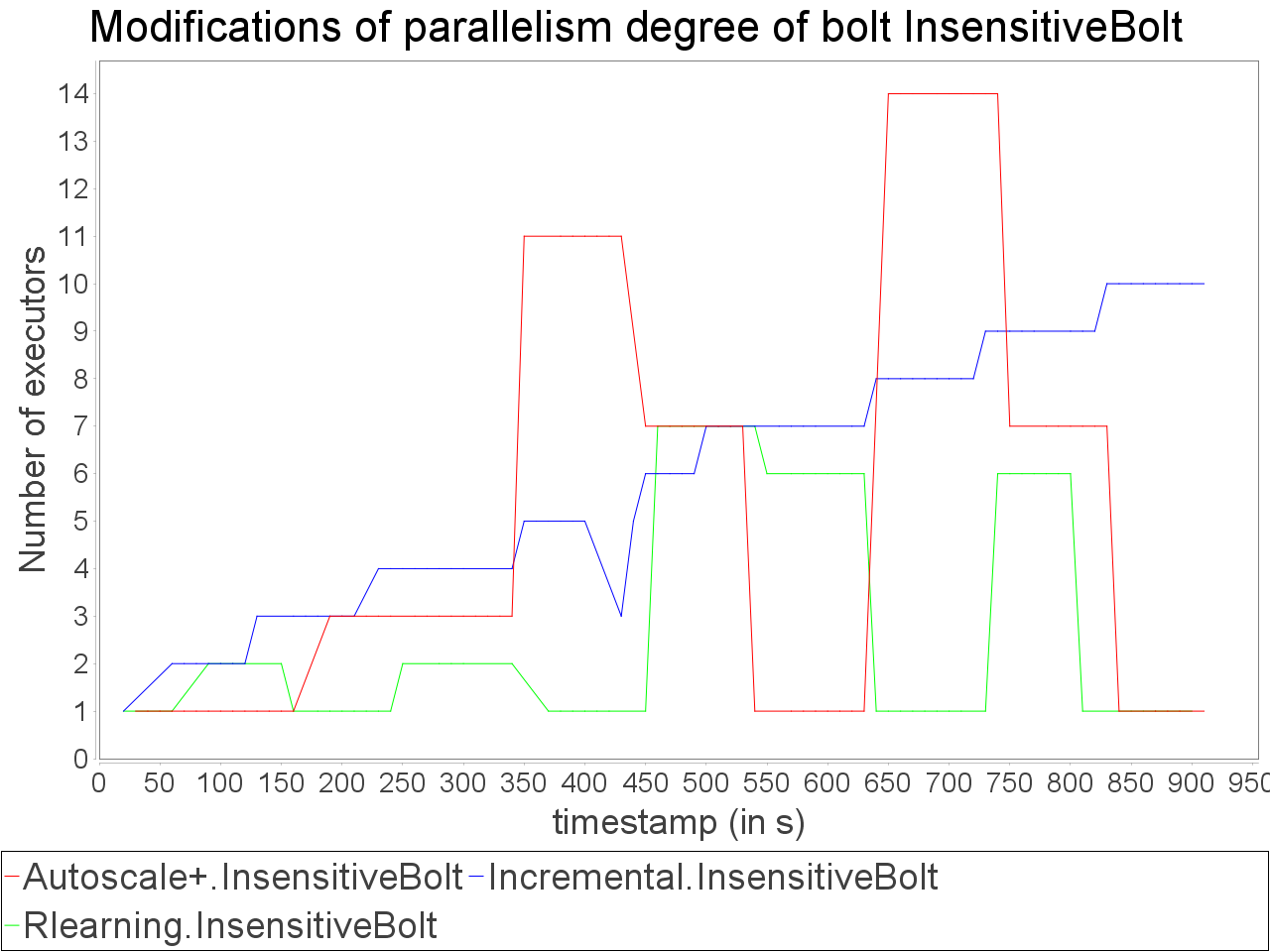 |
Same observations with the erratic stream which has three major peaks in input rate. AUTOSCALE+ adapts the parallelism as peaks appear it decreases when the input rate decreases. With AUTOSCALE+, the overall latency remains stable in comparison to reinforcement learning and incremental strategies which encounter important variations of processing latency.
It is worth noting that sudden peaks in input rate cause tuple losses but the preventive adaptation performed by AUTOSCALE+ limits the degradation of result quality in comparison to reactive approaches.
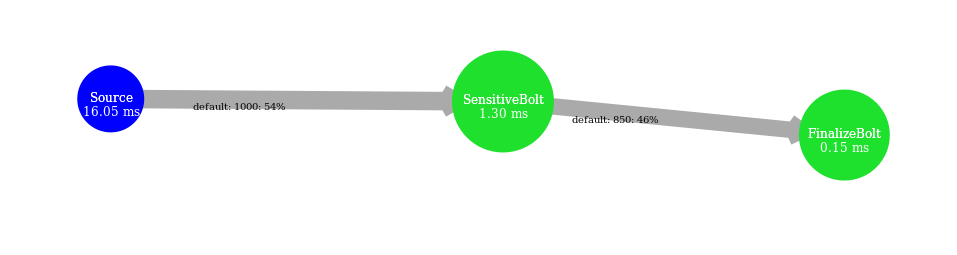
Simple sensitive topology: progressive stream
 | |
 |  |
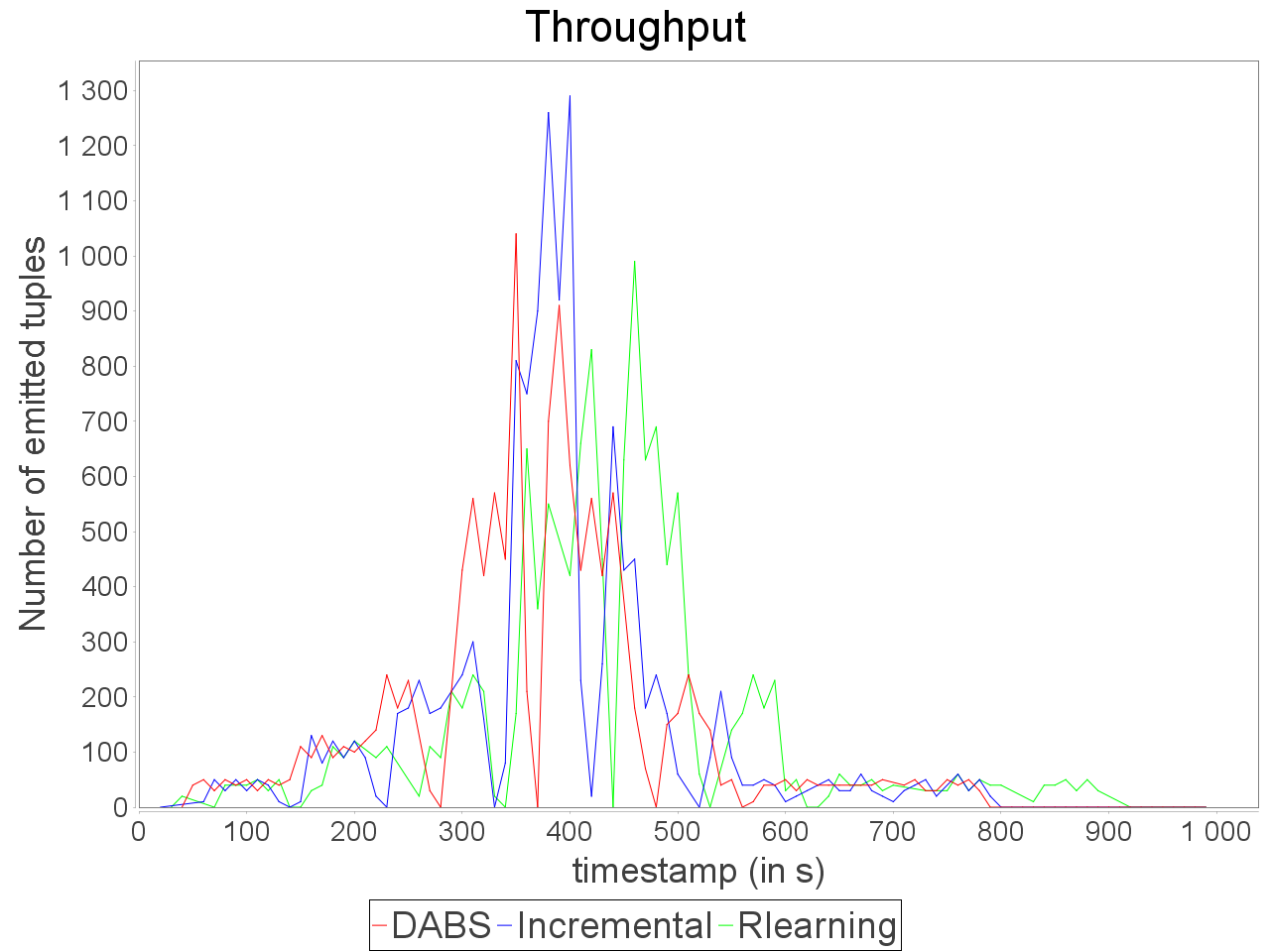 | 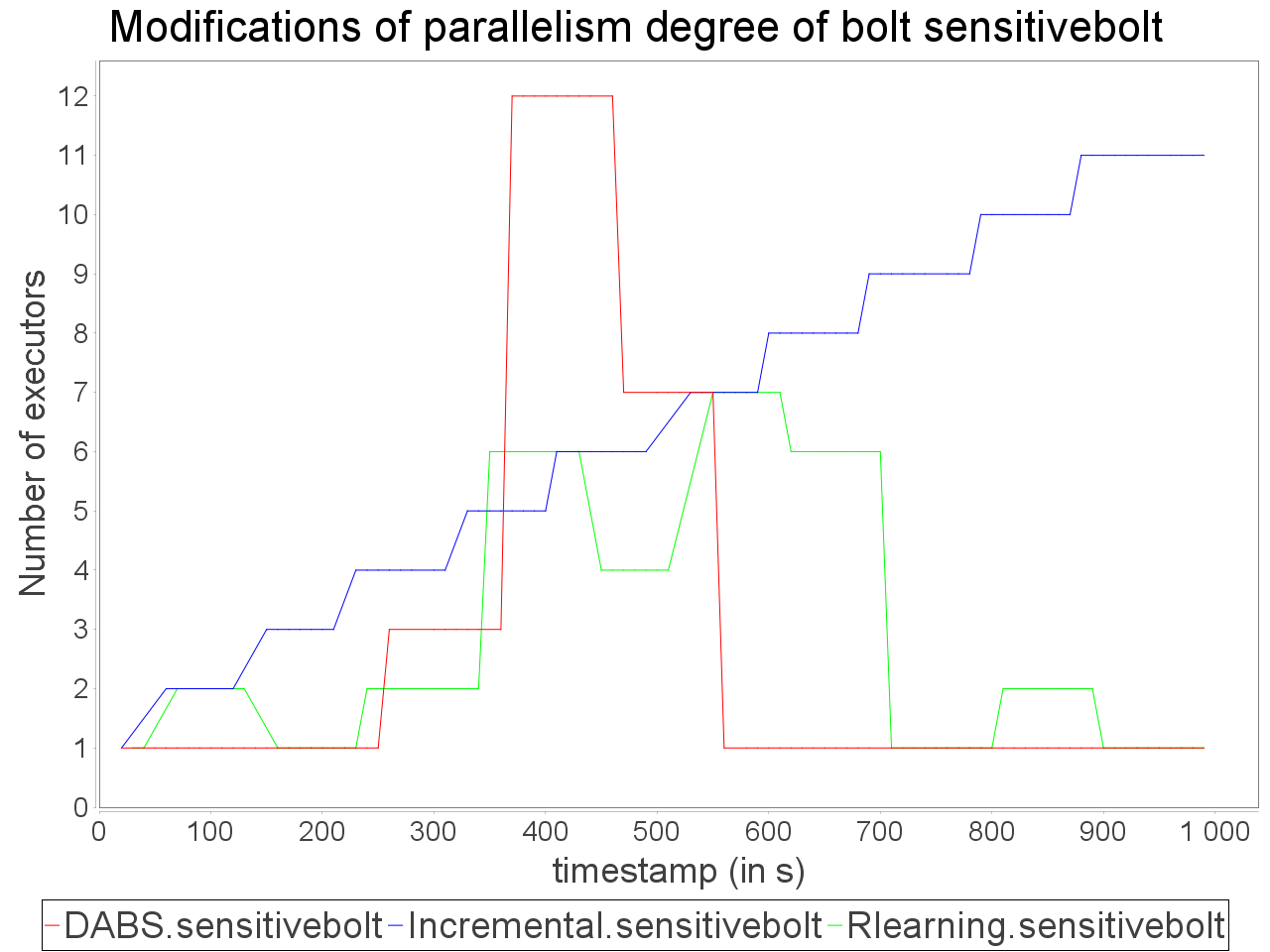 |
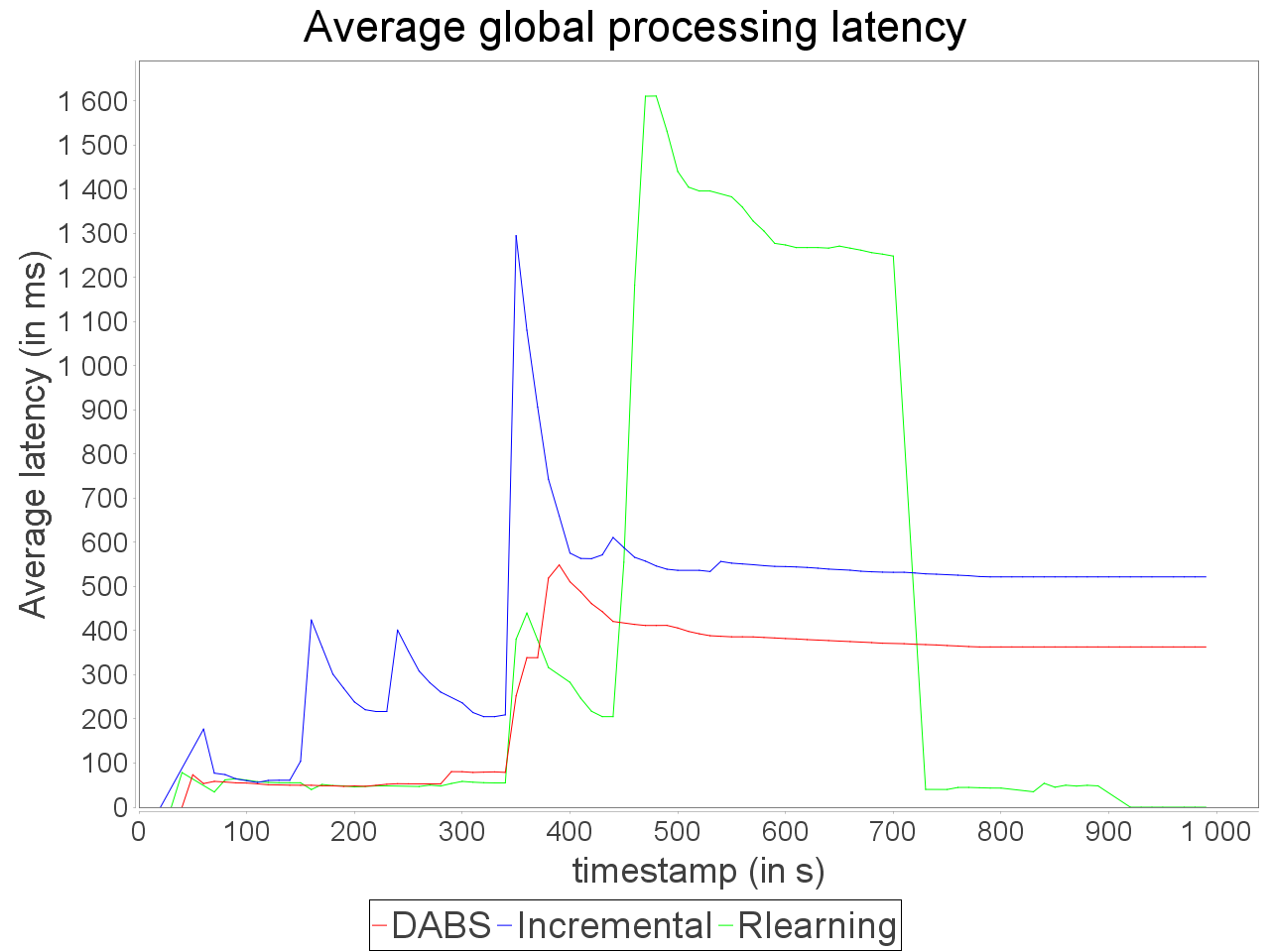
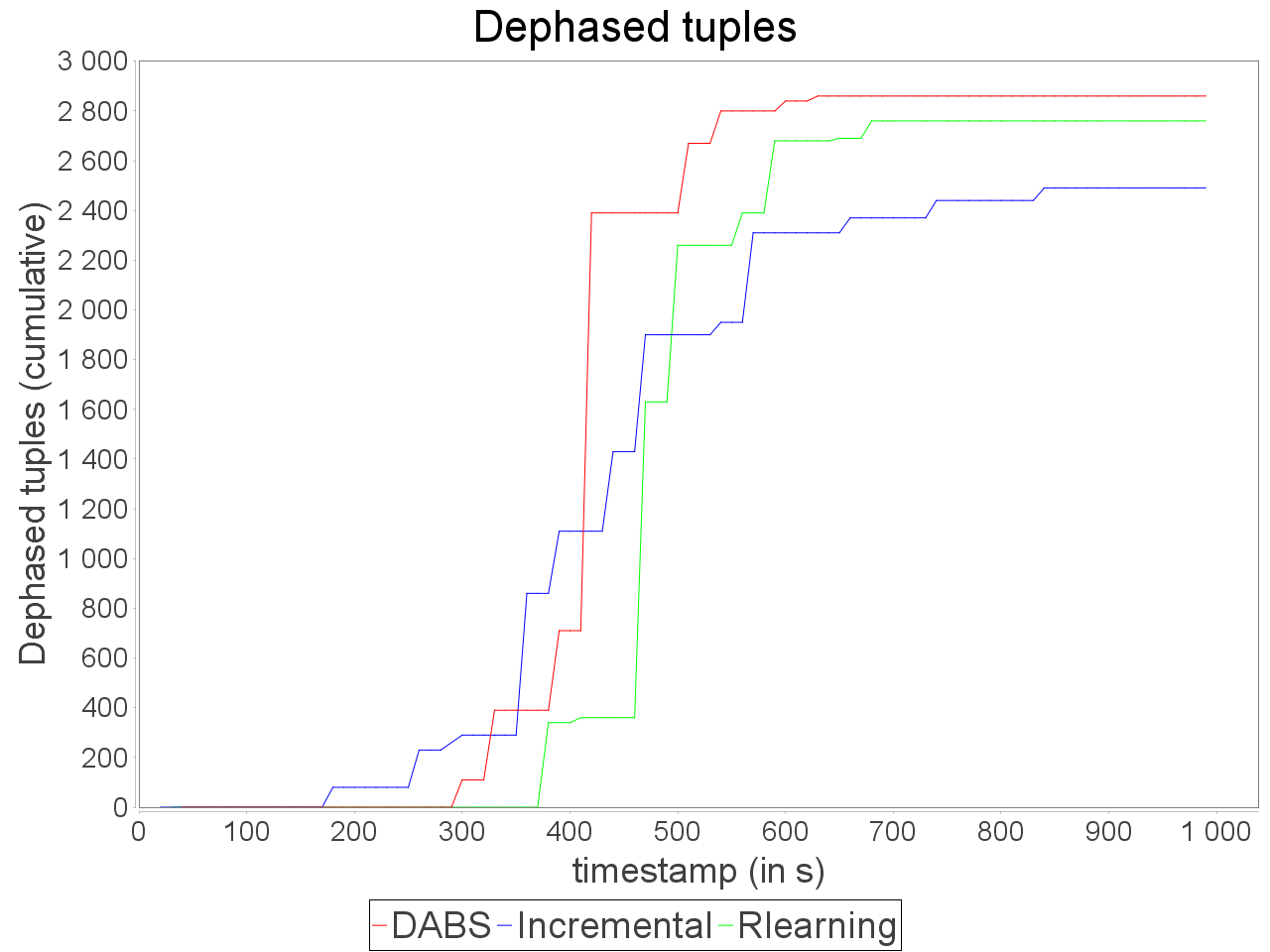
While associating AUTOSCALE+ and OSG, we notice that the evolution of parallelism degree is more accurate than AUTOSCALE+ alone and the average latency is lower even when stream rate increases significantly.
The reinforcement learning scheduler reacts a bit more accurately than in previous cases but after AUTOSCALE+. It leads to difference in processing latency and throughput while processing the stream with the proactive strategy DABS and reactive strategies even with OSG.
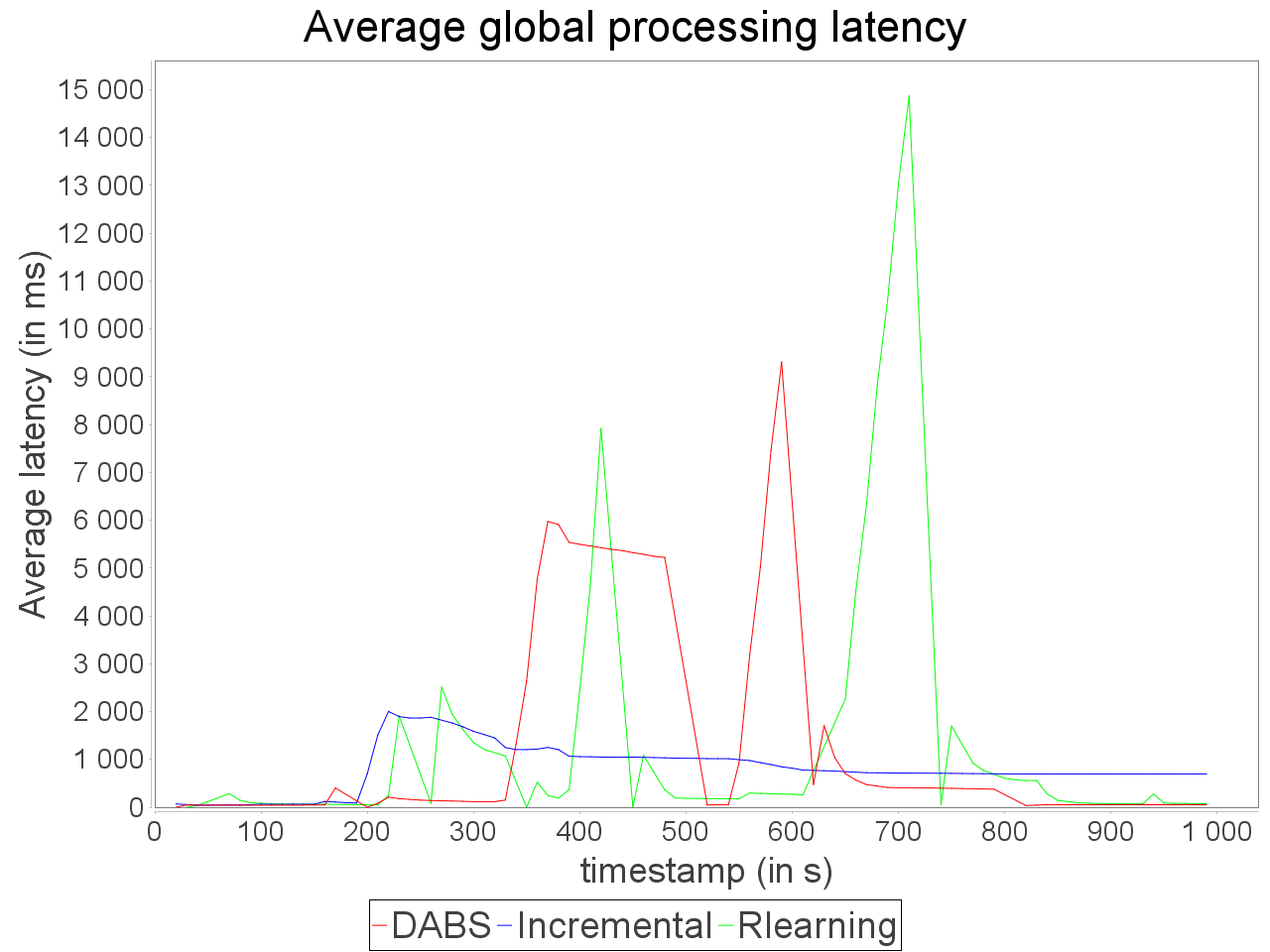
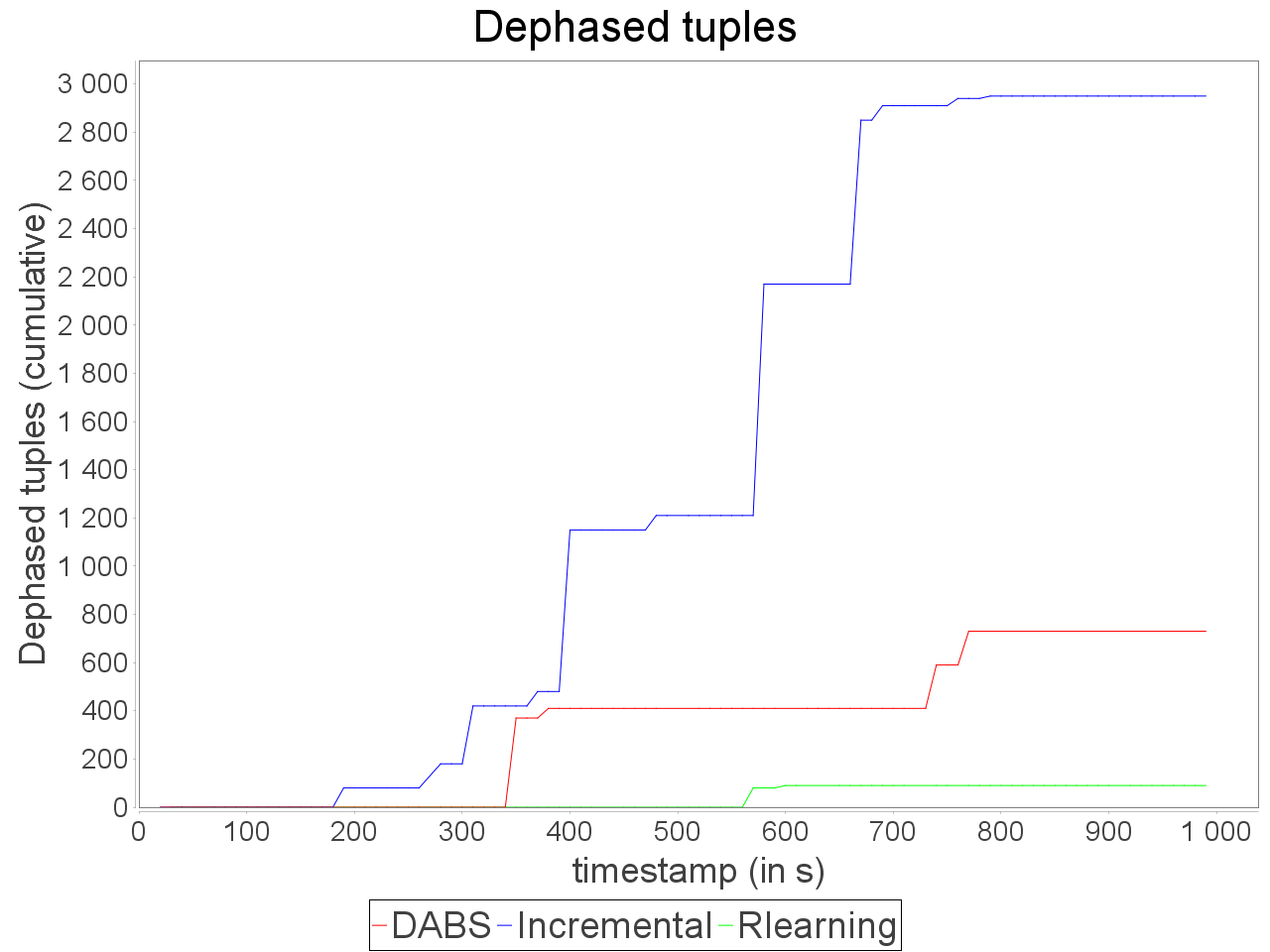
Simple sensitive topology: erratic stream
| |
 |  |
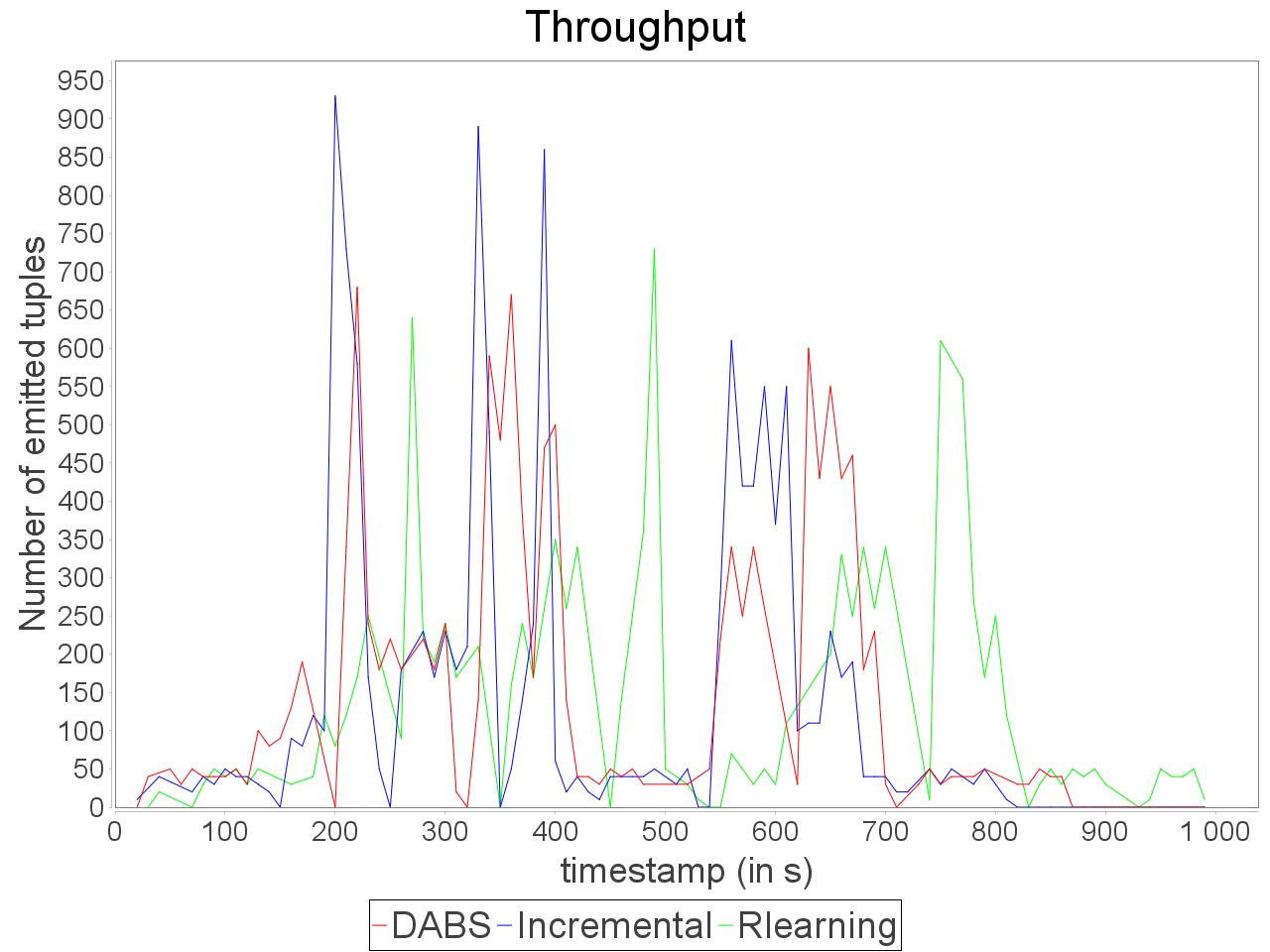 | 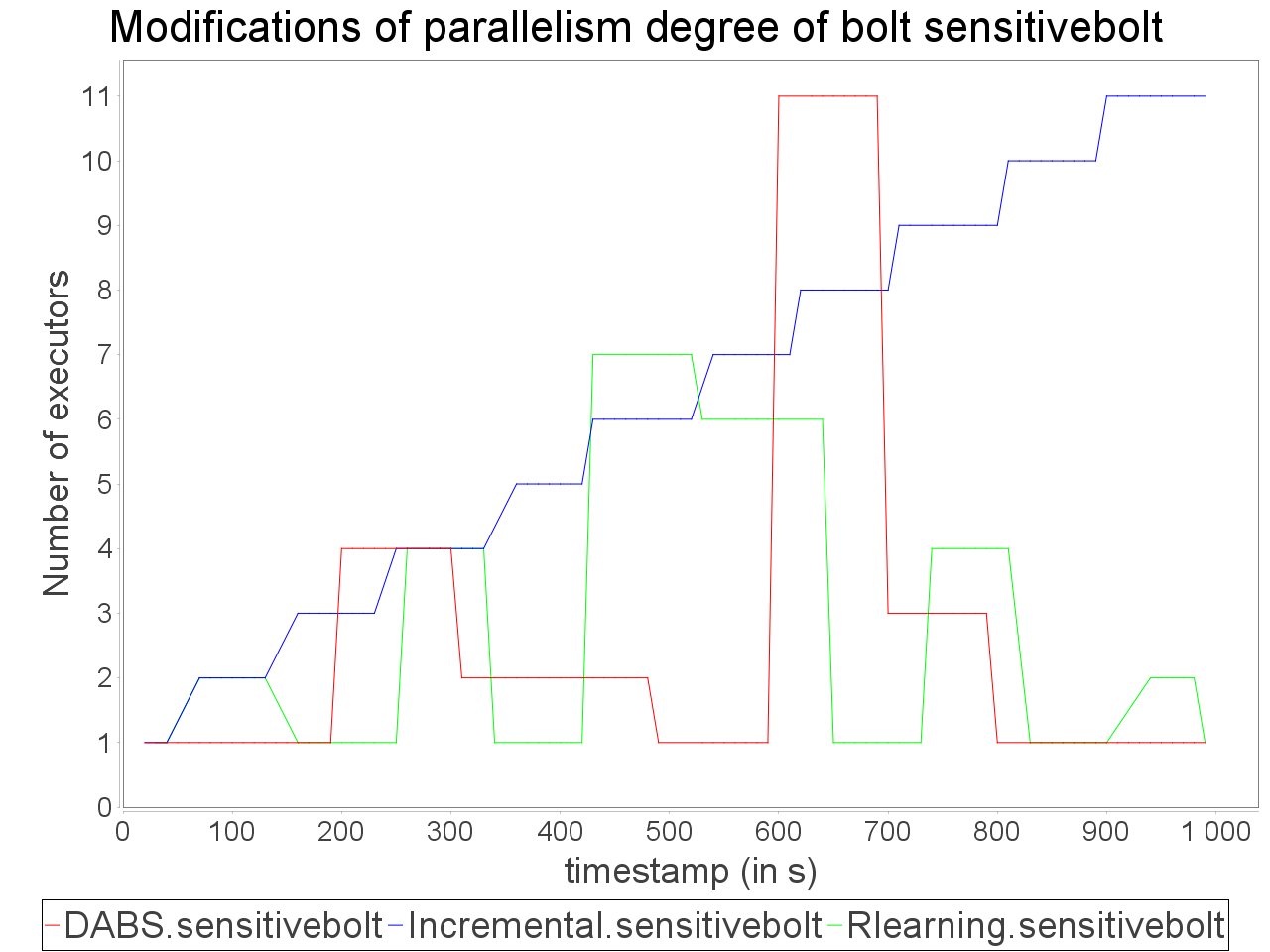 |
In front of an erratic and biased stream, the combination of AUTOSCALE+ and OSG is able to adapt parallelism degree of operators with an equivalent accuracy than the reinforcement learning strategy. Such results can be explained by the ability of OSG to compensate the skew in input data.
It benefits to AUTOSCALE+ because its estimation of processing requirement is based on an even distribution of stream elements between executors. According to this AUTOSCALE+ combined to OSG maintains a stable processing even if a brief and important peak in input rate occurs.
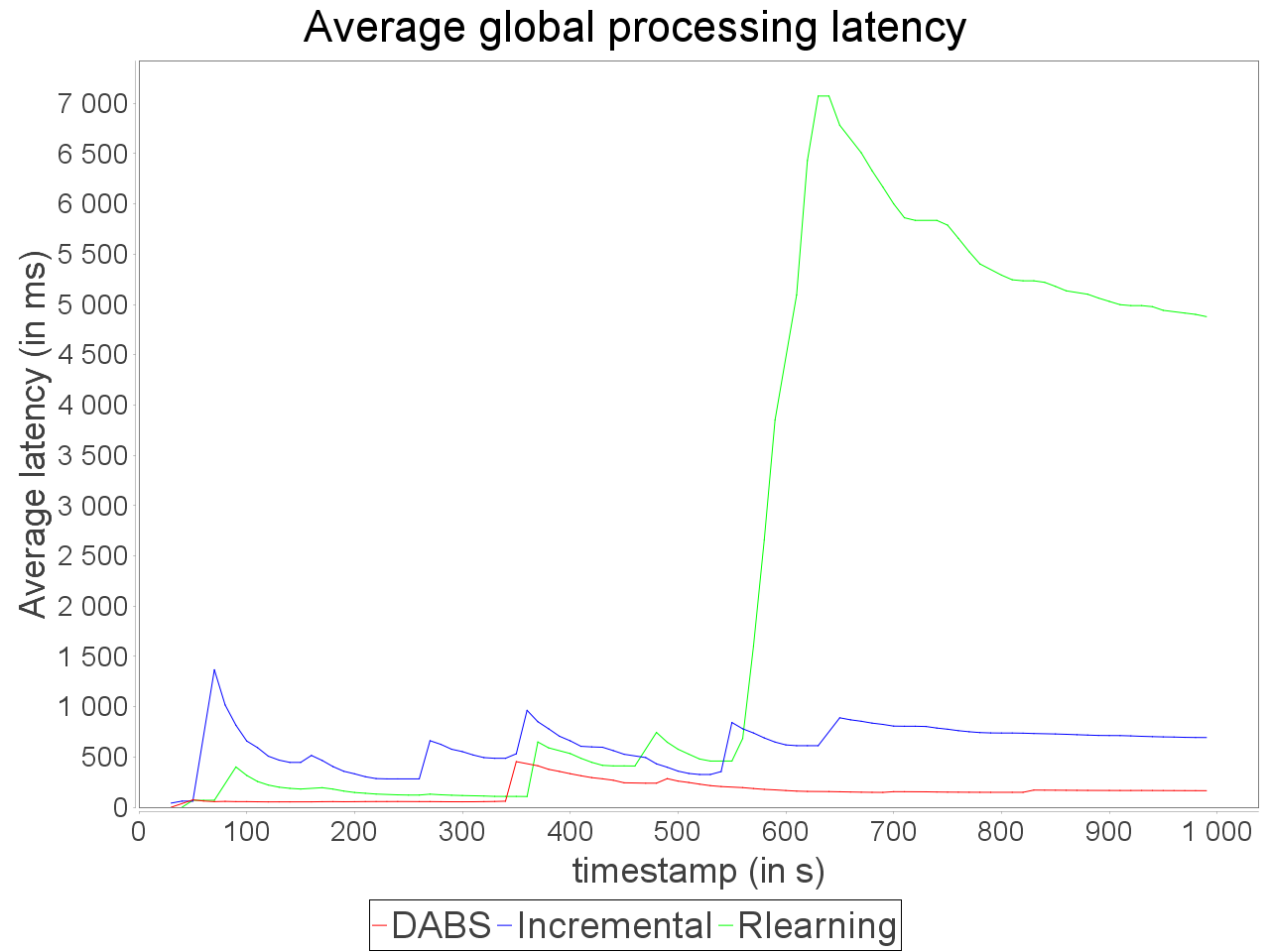
Complex sensitive topology: progressive stream
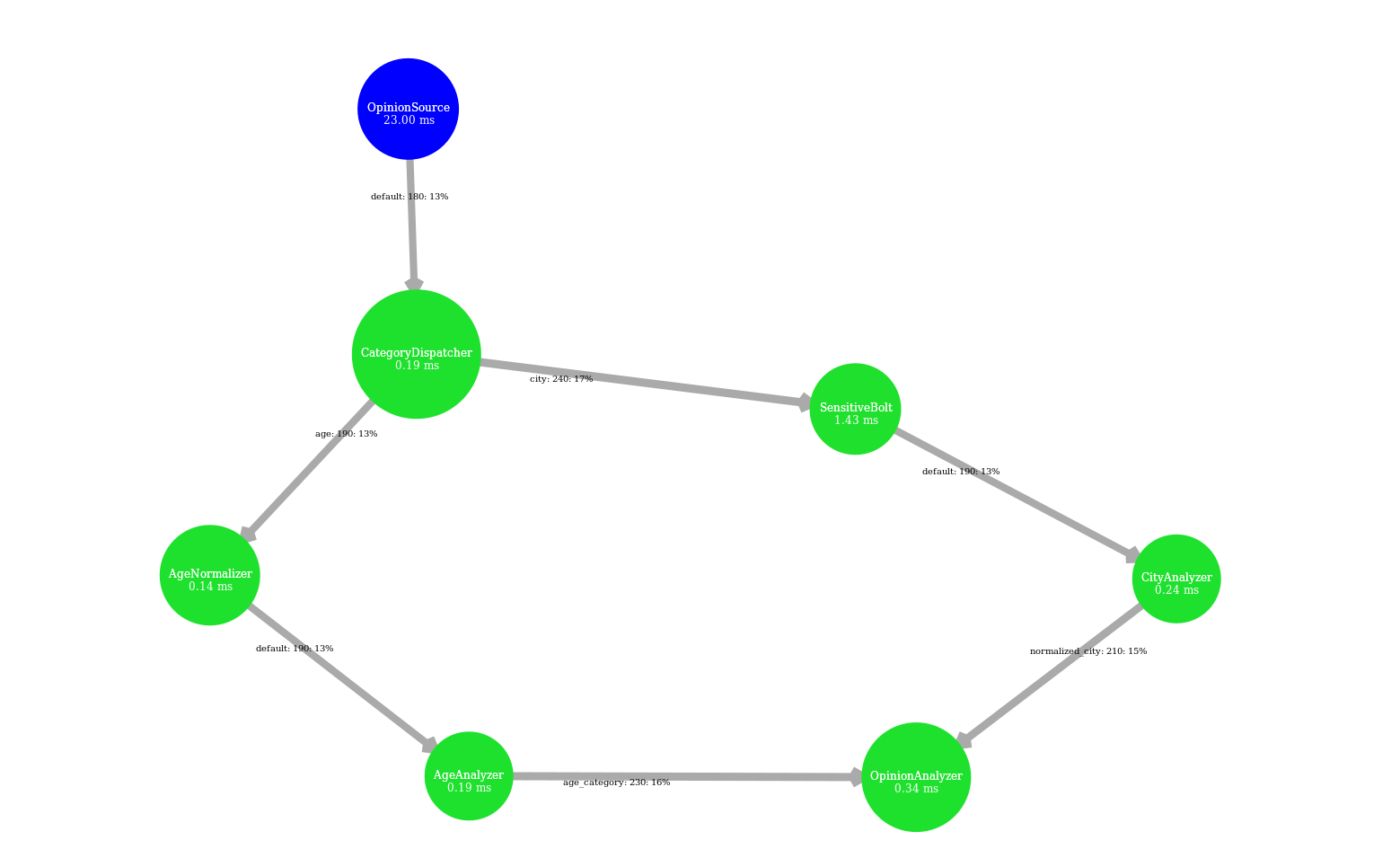 | |
 |  |  |
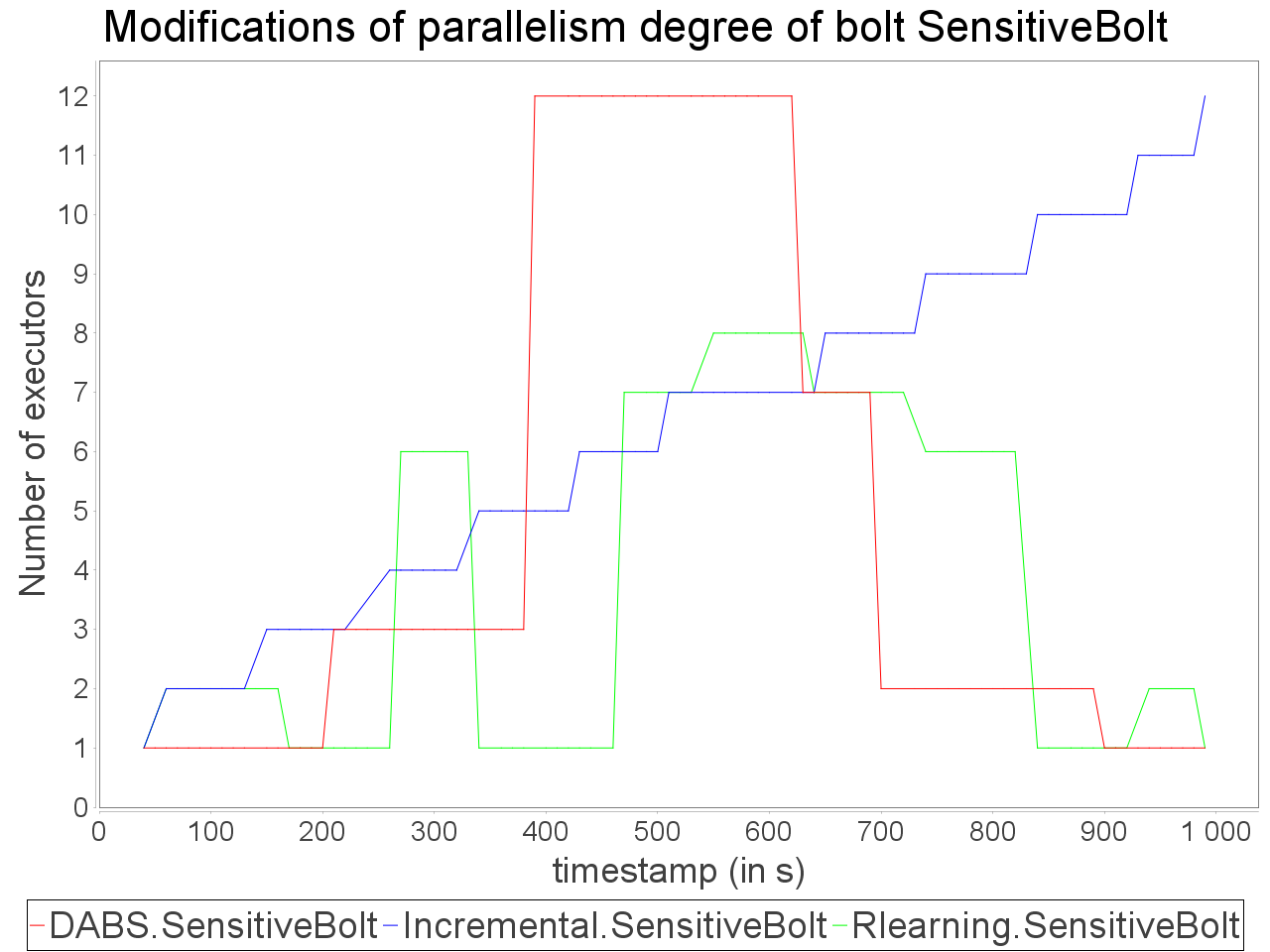 | 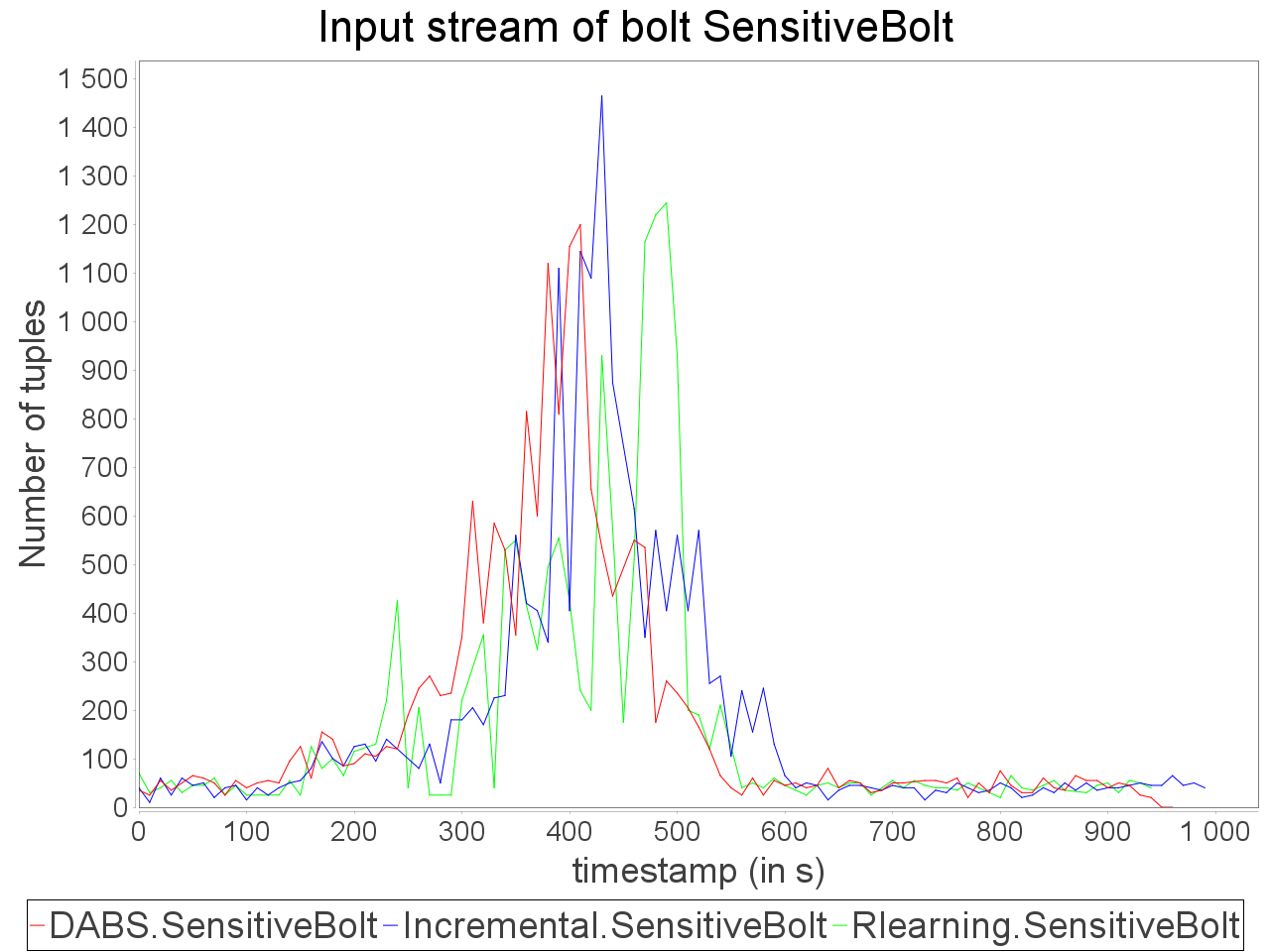 | 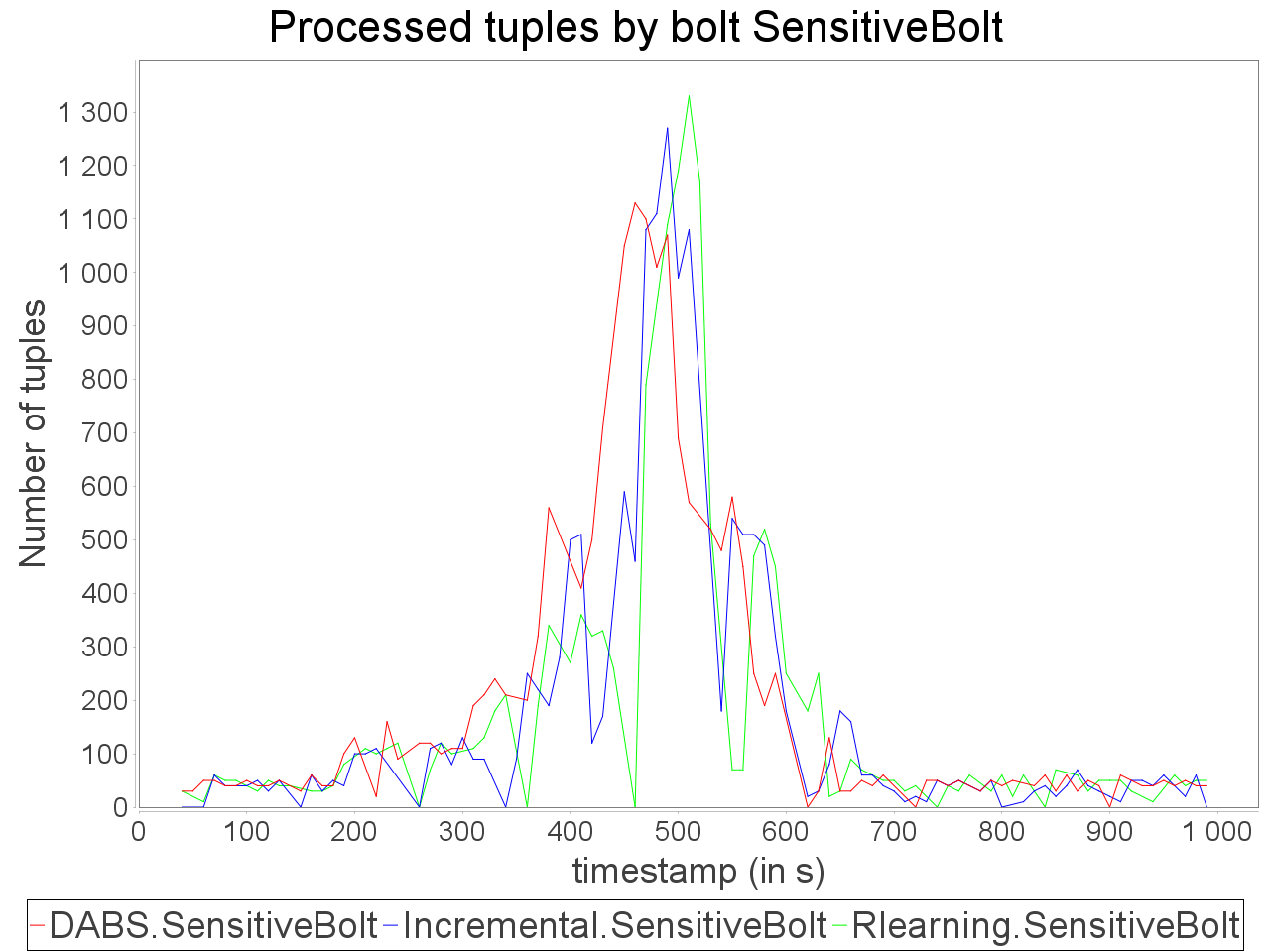 |
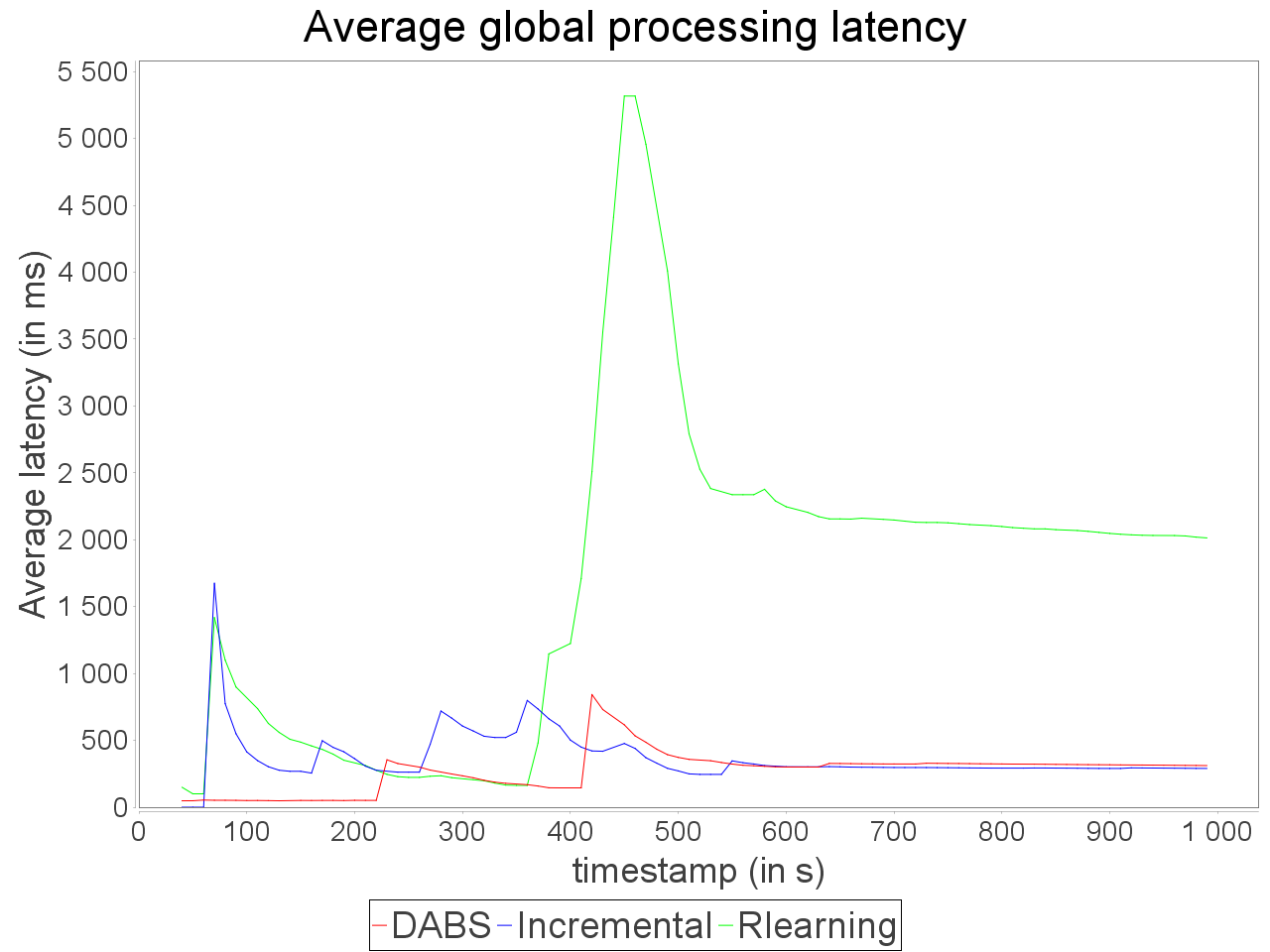
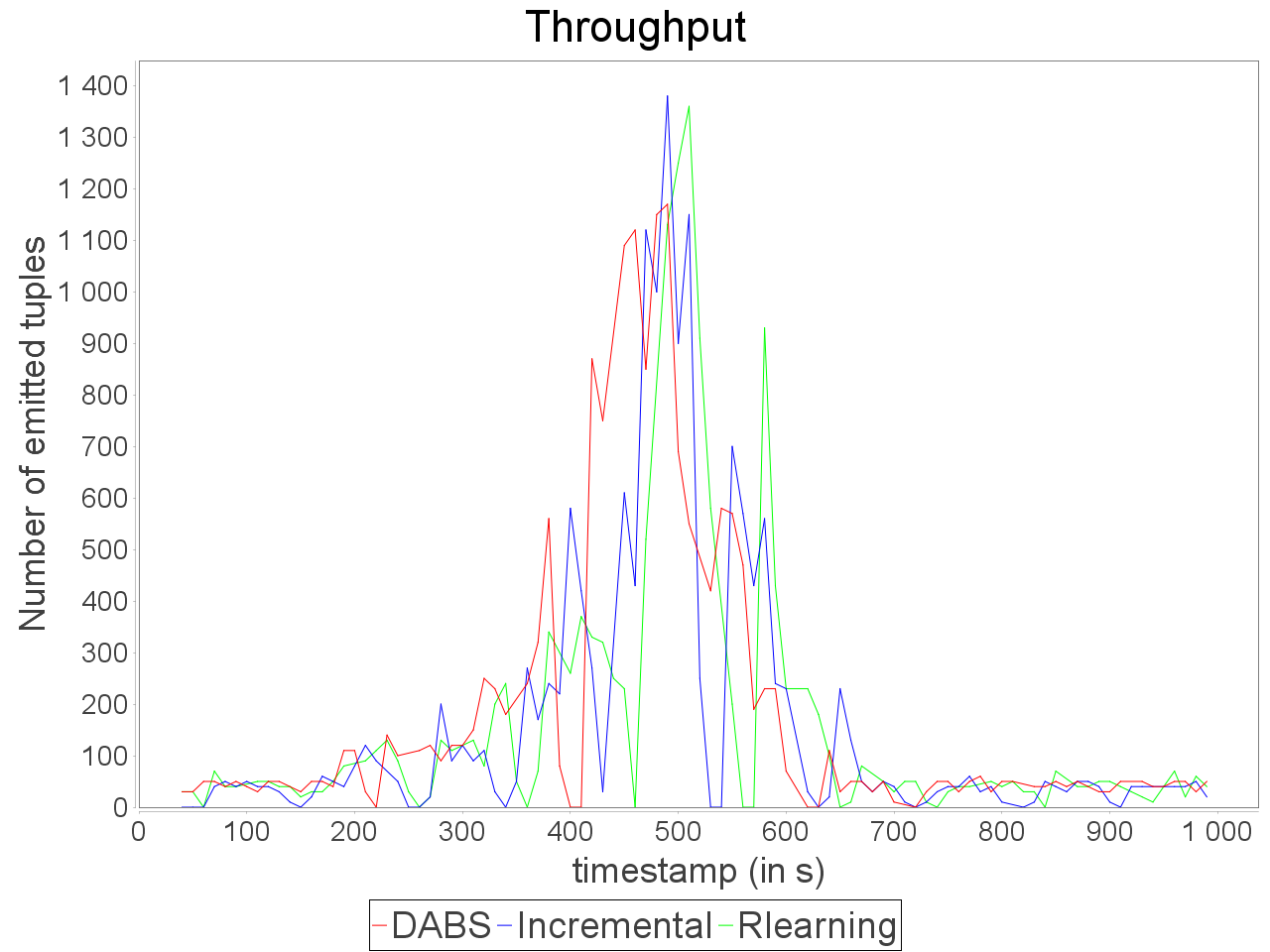
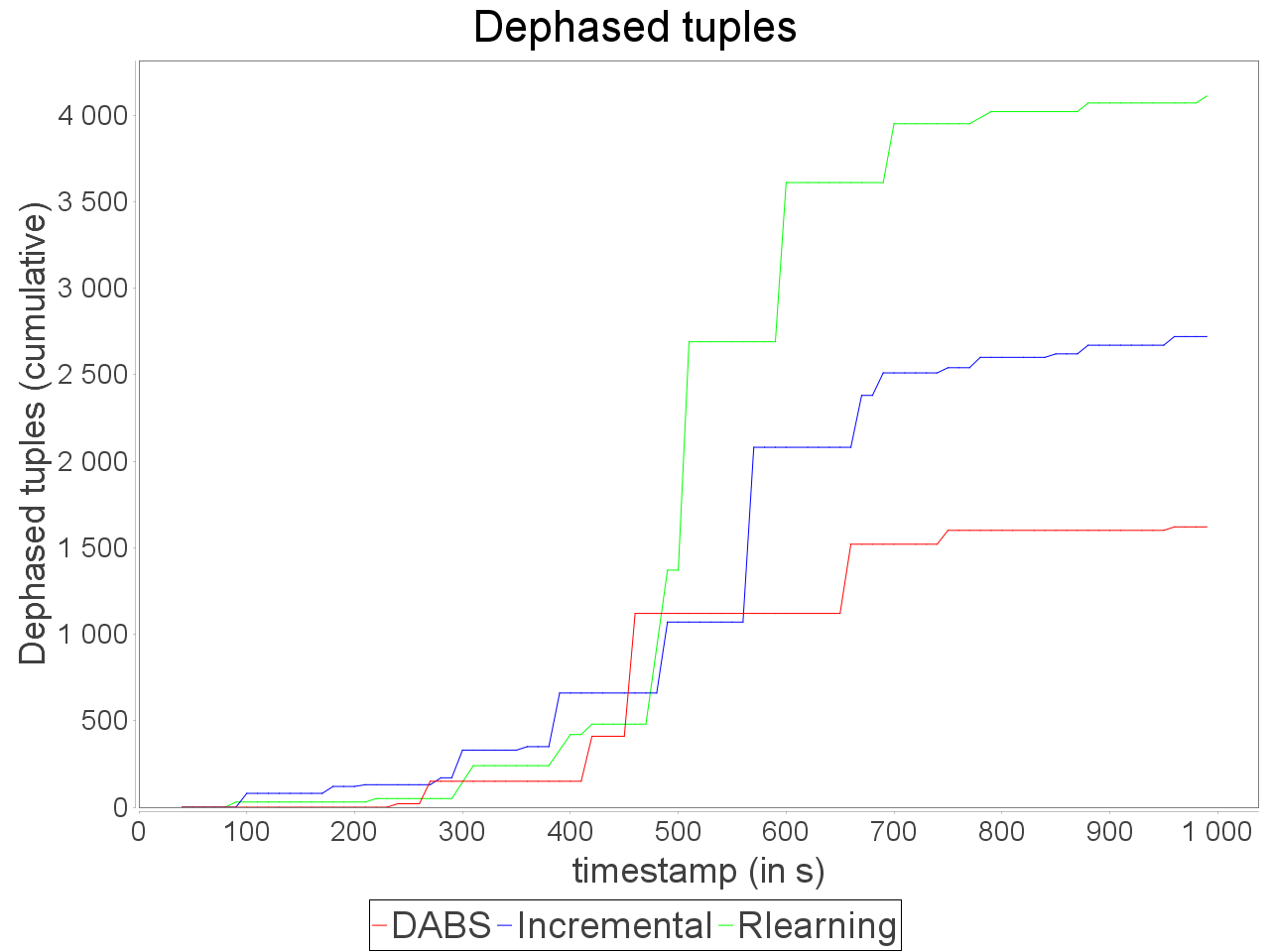
When applied in input of a complex and sensitive topology, DABS maintains a stable end-to-end latency than reactive approaches. It is confirmed by the greater throughput generated with DABS over the observation window. Nevertheless, in a complex topology,
the overestimation of parallelism degree performed by AUTOSCALE+ involves greater reconfiguration overheads (assignments on more supervisors). It is materialized by peaks of out-of-time tuples after important scale-out.
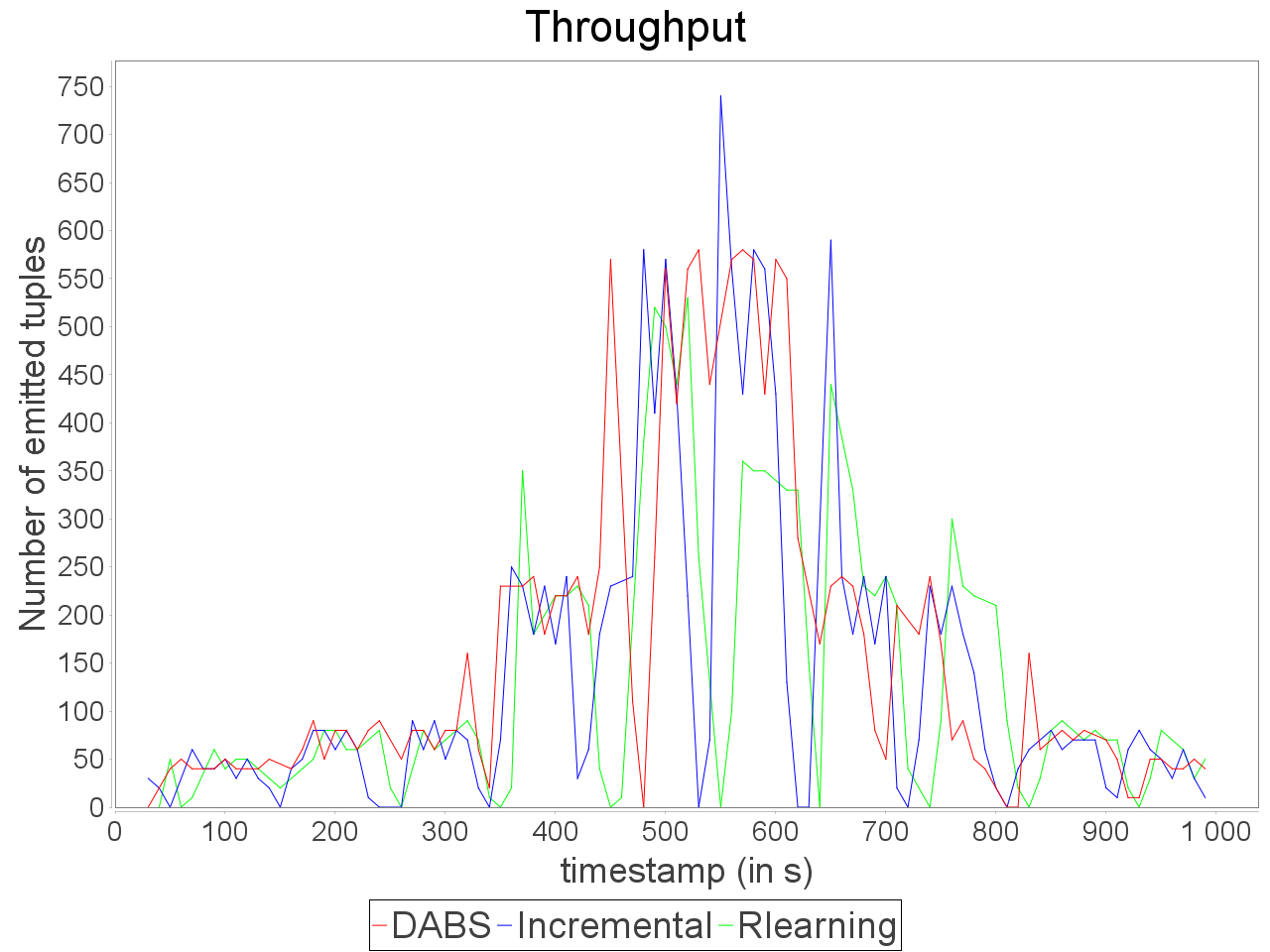
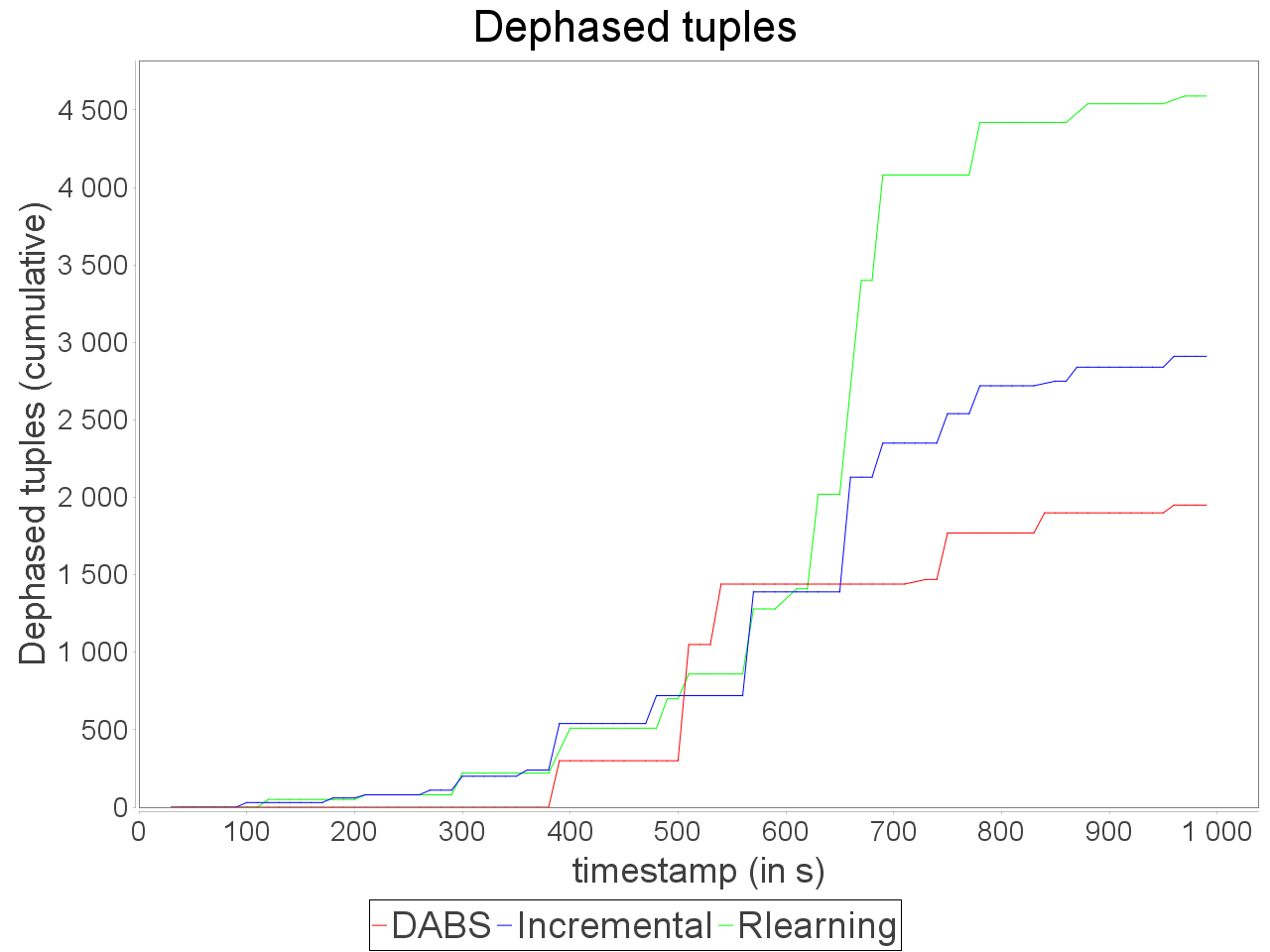
Complex sensitive topology: erratic stream
| |
 |  |  |
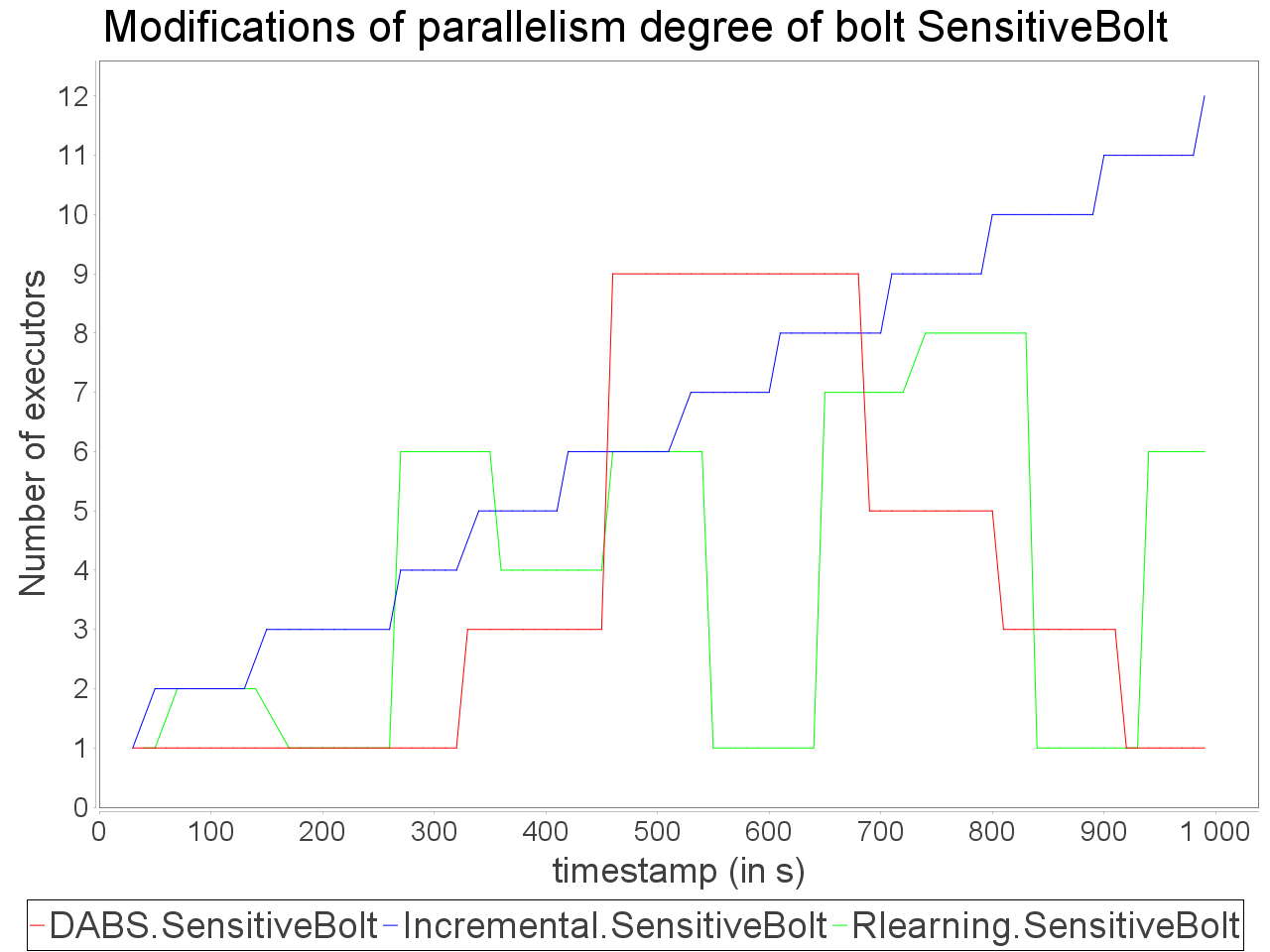 | 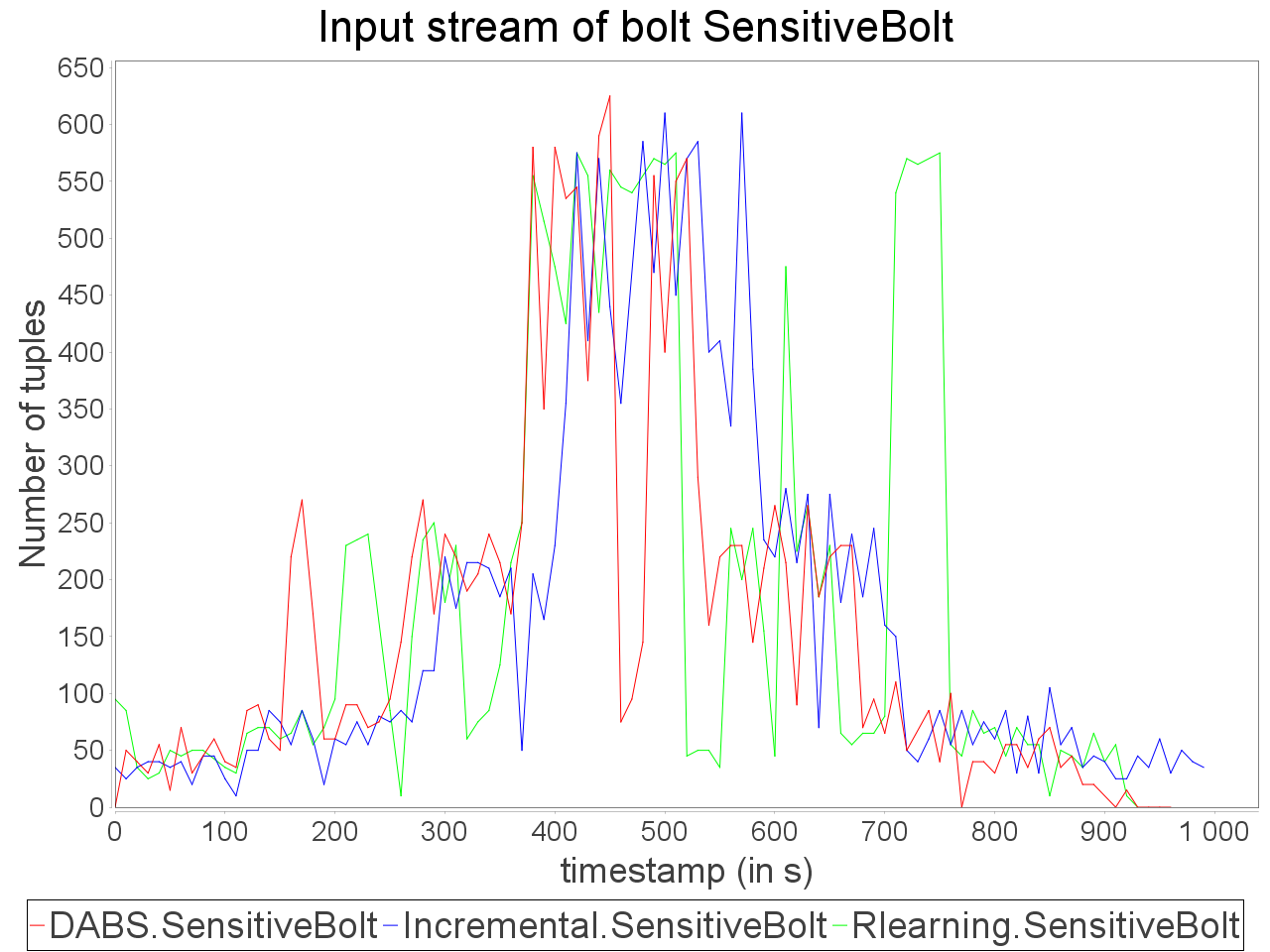 | 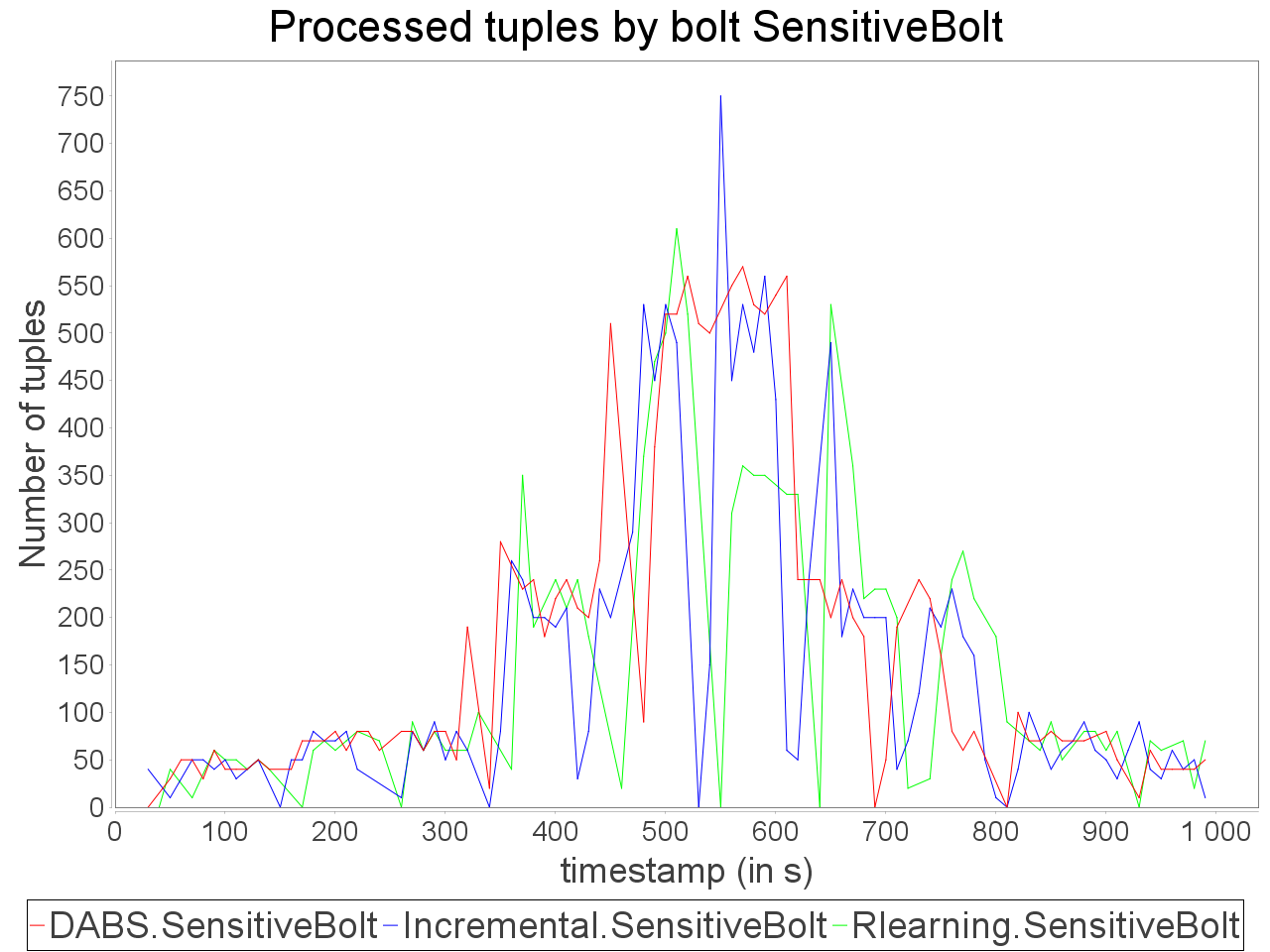 |
When a complex topology receives an erratic stream in input, DABS maintains a stable and low processing latency as explained for the simple sensitive topology. In the same time, the throughput is greater on the observation window than the throughput while using a reactive strategy.
Nevertheless, also as mentioned above, important reconfiguration overheads induced by DABS in a complex topology lead to peaks of out-of-time tuples after important scale-out.
Comparison between Autoscale+ and Autoscale
In order to provide a fair estimation of the gap between Autoscale+ (Autoscale3) and its previous version (Autoscale2), we tested both strategies with the simple sensitive topology. However, we defined three initial configurations to evaluate the behavior of each strategy. The first configuration, sayed UnderSized (US), sets available resources at the half of what is necessary to process the stream.
The second configuration, said Well-Sized (WS), defines proper resources at the start of the execution. Finally, an OverSized (OS) configuration sets resources to the double of what is necessary for treatments.
Comparison with US configuration
| |
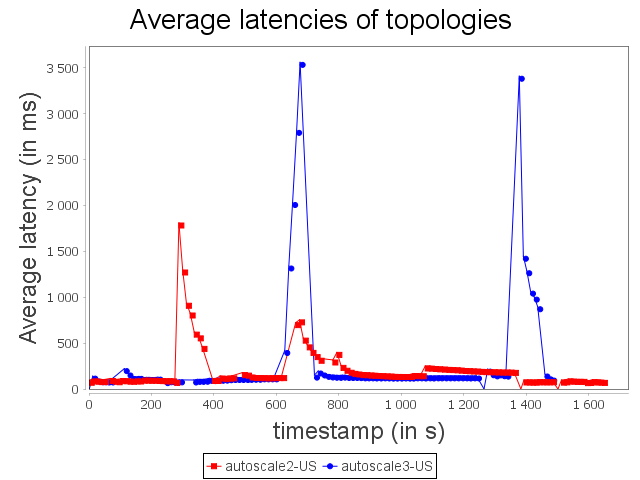 | 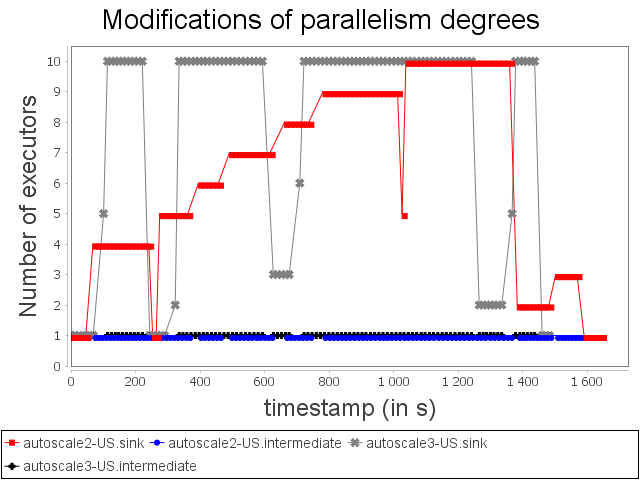 |
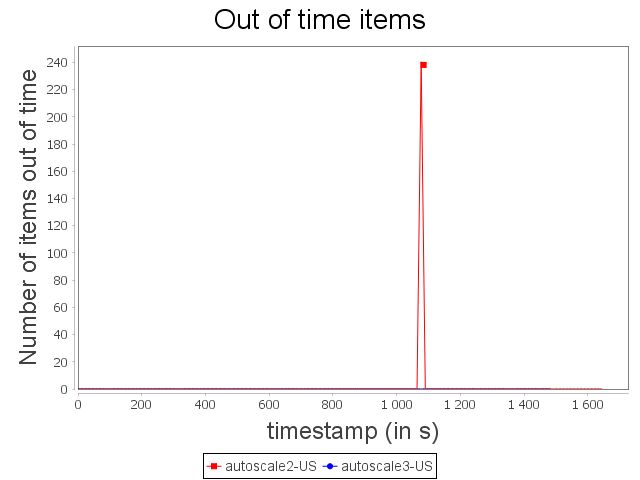 |  |
With the US configuration, we can observe that Autoscale+ is able to avoid loss of items even if it has an impact on end-to-end latency. Actually, as Autoscale+ takes CPU usage into account, scale-out is enabled sooner and larger than Autoscale.
We can also observe that Autoscale+ is more stable than Autoscale as it reconfigures the system less frequently.
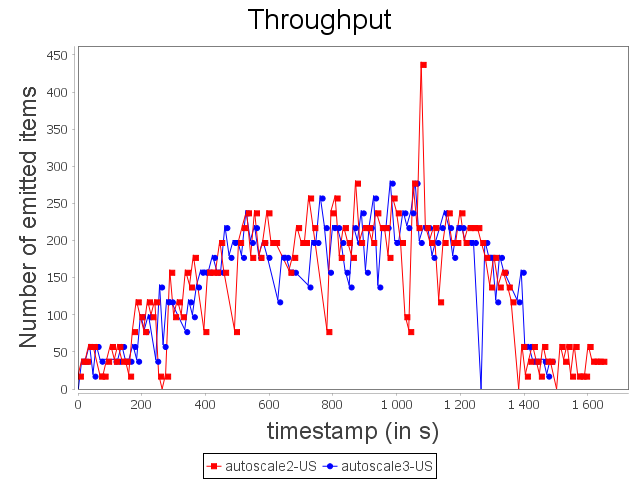
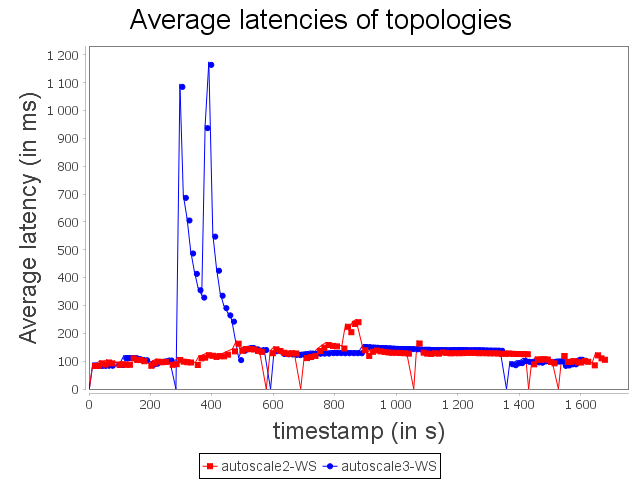
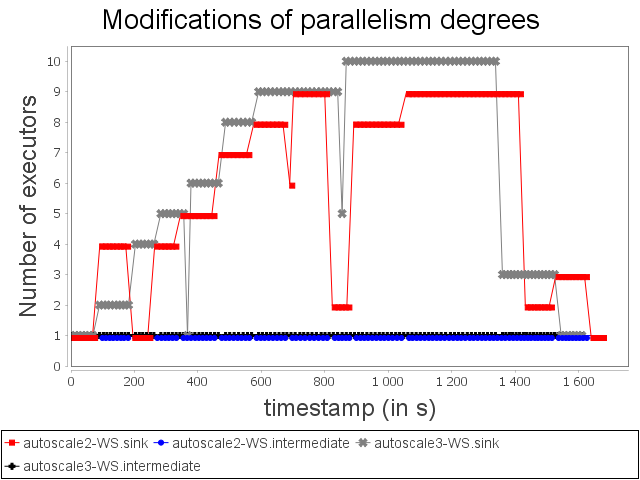
Comparison with WS configuration
| |
 |  |
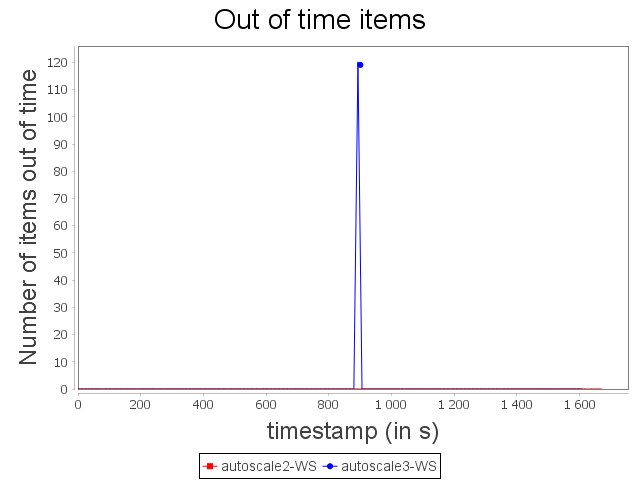 | 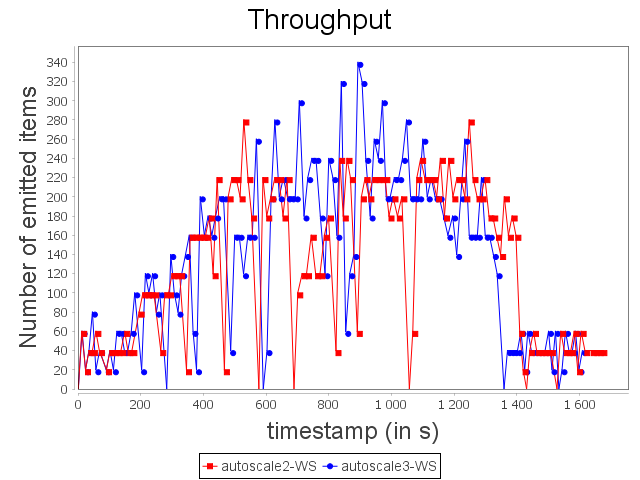 |
With the WS configuration, we can notice that scale-out performed by Autoscale+ has a greater impact on processing latency. Nevertheless, the increase of the processing latency is quickly decreased. As observed previously, Autoscale+ is more stable than Autoscale which involves a more stable throughput over the complete treatment.
Even if some items have not been processed within the time threshold, it did not have a major impact on throughput.
Comparison with OS configuration
| |
 |  |
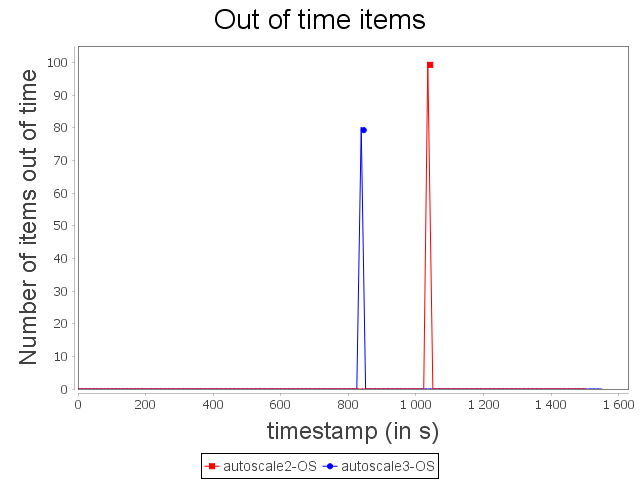 | 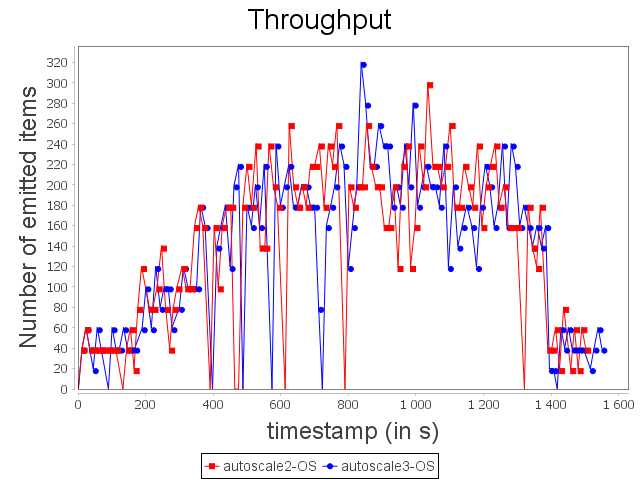 |
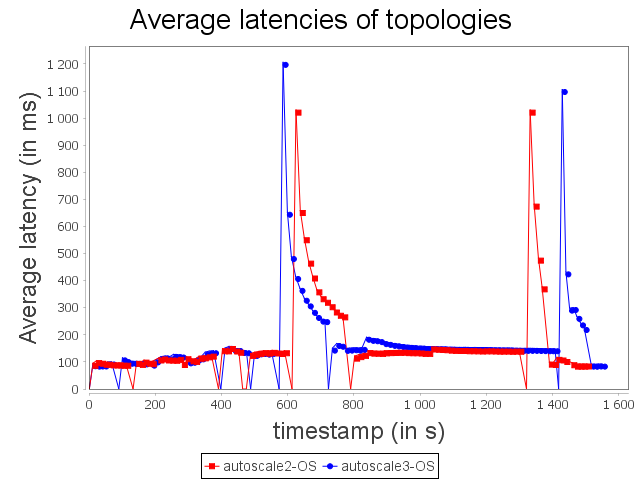
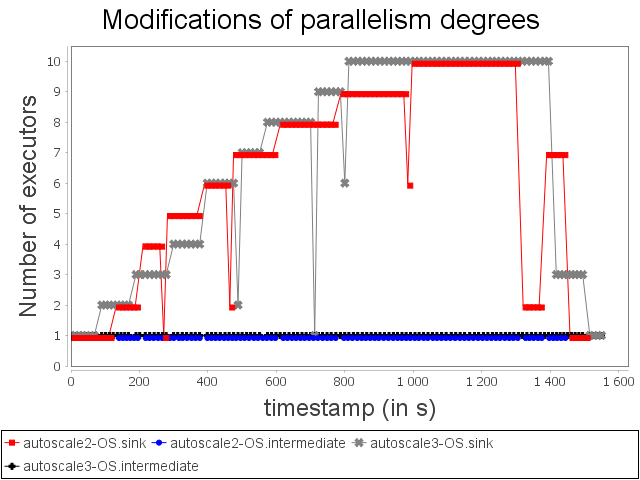
With the OS configuration, Autoscale+ takes advantage of its estimation based on CPU usage to increase and decrease more progressively the parallelism degree of the sensitive bolt. While, Autoscale decreases brutally the parallelism degree of the operator and then increases it right after, Autoscale+ decreases once the parallelism degree of the operator.
As a consequence, Autoscale+ generates less violation of processing time than Autoscale.
Downloads
DABS v1.0 (Autoscale+ scheduler and OSG custom grouping)
This version of DABS is exclusively compatible with Apache Storm 1.0.2 and later because of package namespaces.
| AUTOSCALE+ v3.0 (sources) | Download sources |
| OSG (sources) | Download sources |
| DABS HOWTO | Download pdf |
| Monitoring database SQL script | Download SQL script |
Topologies
| Topologies + synthetic loads(sources) | Download zip file |
| Topologies + synthetic loads (jar) | Download zip file |
Contact
For any questions about AUTOSCALE, contact us at following address:
Email: roland.kotto-kombi@liris.cnrs.fr
Email: roland.kotto-kombi@liris.cnrs.fr